9 Logistische Regression
Wenn wir diskrete oder kategorielle Grössen modellieren wollen, ist das allgemeine lineare Modell nicht geeignet, da dieses eine kontinuierliche abhängige Variable voraussetzt. Oft haben wir zum Beispiel eine zweiwertige kategorielle abhängige Variable (mit den Werten Event und kein Event). Gibt es eine Möglichkeit, diesen Wertebereich auf ein Kontinuum abzubilden? Kann man das Allgemeine Lineare Modell (LM) verallgemeinern und damit Modelle für diskrete und kontinuierliche abhängige Variable in einer einzigen statistischen Methodologie zusammenführen?
Die Antwort darauf hat den Namen Generalisierte Lineare Modelle (GLM) (also nicht zu verwechseln mit dem Allgemeinen Linearen Modell (LM)). Dazu gehören zum Beispiel die Poisson-Regression (die wir später behandeln werden) sowie die logistische Regression, die wir hier studieren. Zu den GLM gehören als Spezialfall aber auch die bereits eingeführte multiple Regression und Varianzanalyse als Vertreter der Linearen Modelle.
Ein Beispiel für eine logistische Regression ist, wenn man z.B. mit Hilfe der Variablen Geschlecht, Krankheitsstadium, Tumorgrösse und Alter die Wahrscheinlichkeit bestimmen möchte, ob jemand seine Krebserkrankung überlebt, oder nicht.
\[ \def\logit{\text{logit}} \def\Var{\text{Var}} \]
9.1 Notation und R
\(O\): Odds
\(OR\): Odds Ratio
\(\pi\): Wahrscheinlichkeit, Risiko
\(\logit(\pi)\): \(\log\frac{\pi}{1-\pi}=\log Odds\)
\(\exp(x)\): \(e^x\)
\(X \sim \mathcal{B}(n,\pi)\): \(X\) ist binomialverteilt mit Parameter \(n\) und \(\pi\)
\(E(X)\): Erwartungswert einer Zufallsvariable \(X\)
\(\eta=\beta_0+\beta_1x_{1}+\beta_2x_{2}+\dots+\beta_m x_{m}\): linearer Prädiktor
R:packet::funktion(): Alternative Syntax zulibrary(packet)gefolgt vonfunktion()R:glm(): Funktion zum Anpassen von GLM’s.
9.2 Lernziele
Beachten Sie im Folgenden die überaus wichtigen Rechenregeln bezüglich der \(\log\) und \(\exp\)-Funktion, die wir bereits kennengelernt haben. Sie werden uns auf Schritt und Tritt verfolgen:
\[\begin{align} \log(a \times b) &= \log(a) + \log(b)\\ \log(a /b) &= \log(a) - \log(b)\\ \exp(a + b) &= \exp(a) \times \exp(b)\\ \quad \exp(a-b) &= \exp(a)/\exp(b) \end{align}\]
Lernziele
Wenden Sie eine logistische Regression an, wenn anhand einer oder mehrerer Prädiktorvariablen die Odds \(O_i\) und die Wahrscheinlichkeit \(\pi_i\) für ein Ereignis (d.h. bei binärer abhängigen Variable) für die Einheit \(i\) geschätzt werden sollen.
Beachten Sie, dass bei einer logistischen Regression die \(\logit(\pi_i):=\log Odds_i\) modelliert werden. Der lineare Prädiktor \(\eta_i\) ist dann der transformierte Erwartungswert,
\[ \boxed{\logit(\pi_i) = \eta_i=\beta_0 + \beta_1x_{i1}+\dots+\beta_m x_{im}.} \]
Berechnen Sie die geschätzten \(\logit(\hat{\pi}_i)\) durch Einsetzen der geschätzten Regressionskoeffizienten \(\hat{\beta}_k (k=0,\dots,m)\) sowie der Werte für die Prädiktoren der Einheit \(i\) in die Regressionsgleichung.
Interpretieren Sie \(\beta_0\) (intercept) als \(\logit(\pi_i)\) für das Ereignis, wenn alle unabhängigen quantitativen Variablen den Wert 0 annehmen und die Kategorie der unabhängigen kategoriellen Variablen die Referenzkategorie ist.
Interpretieren Sie die \(\beta_k\) (\(k=1,\dots,m\)) als einen Unterschied auf der \(\logit\)-Skala für zwei Subpopulationen, die sich auf \(x_k\) um eine Einheit unterscheiden, während die anderen unabhängigen Variablen konstant gehalten werden. Die Nullhypothesen sind dann meistens \(H_0: \beta_k = 0\), \(k=1,...,m\).
Eine Differenz auf der \(\logit\) Skala entspricht einem \(\log(OR)\).
Interpretiere die \(\exp(\beta_k)\) (\(k=1,\dots,m\)) als das \(OR_k\) für das Ereignis für zwei Subpopulationen, die sich auf \(x_k\) um eine Einheit unterscheiden, während die anderen unabhängigen Variablen konstant gehalten werden. Die Nullhypothesen sind dann meistens \(H_0: OR_k = 1\), \(k=1,...,m\).
Berechnen Sie die Wahrscheinlichkeiten \(\pi_i\) aus dem linearen Prädiktor mit der logitistischen Funktion,
\[ \boxed{\pi_i = \frac{O_i}{1+O_i}=\frac{\exp(\eta_i)}{1+\exp(\eta_i)}.} \]
Führen Sie eine logistische Regression in
Rdurch und interpretieren Sie die Regressionskoeffizienten sowie deren inferenzstatistischen Angaben.Erklären Sie den zentralen Begriff der Likelihood: Die Likelihood eines Parameterwertes \(L(\theta)\) ist die Wahrscheinlichkeits(dichte) der beobachteten Daten \(x\), gesehen als eine Funktion des Parameters \(\theta\),
\[ L(\theta)=p(x;\theta). \]
Sie wissen, dass man im Falle der logistischen Regression Parameter mit der Maximum-Likelihood-Methode geschätzt und getestet werden.
Sie können zwei verschachtelte logistische Regressionsmodelle mit einem Likelihood Ratio Test vergleichen mit \(H_0\): Das reduzierte Modell stimmt.
9.3 Vorhersage von Diabetes
Wir verwenden für dieses Kapitel einen Datensatz von Pima-Indianern. Dieser Datensatz stammt ursprünglich vom National Institute of Diabetes and Digestive and Kidney Diseases. Ziel ist es, auf Grundlage verschiedener Prädiktoren diagnostisch vorherzusagen, ob eine Patientin Diabetes hat oder nicht.
Zu didaktischen Zwecken wurde der Datensatz vereinfacht (Entfernung aller Beobachtungseinheiten mit fehlenden Werten) bzw. werden nicht alle Variablen berücksichtigt.
Die Variable
pregnant_binexistiert im Originaldatensatz nicht, sie wurde zu didaktischen Zwecken aus der Variablepregnanterstellt (0 = Nein, >0 = Ja).
Code book zum Datensatz (\(n\) = 392)
| Variable | Beschreibung |
pregnant |
Anzahl bisheriger Schwangerschaften |
pregnant_bin |
Schon eine Schwangerschaft gehabt (0 = Nein, 1 = Ja) |
glucose |
Plasma-Glukose-Konzentration (mg/dl) |
pressure |
Diastolischer Blutdruck (mmHg) |
triceps |
Faltendicke beim Triceps (mm) |
mass |
Body Mass Index (kg/m^2) |
pedigree |
Diabetes Pedigree Funktion (PDF) |
age |
Alter (Jahre) |
diabetes |
Diabetes (neg, pos) |
- Die abhängige Variable
diabetesist hier eine zweiwertige nominale Variable, \(Y_i=\{0,1\}\). - Bemerkung: Bei gruppierten Daten ist \(Y_i\) manchmal die Anzahl Ereignisse in einer Gruppe \(i\) mit \(n_i\) Einheiten.
9.4 Warum keine lineare Regression?
Wenn die abhängige Variable binär ist (also nur die Werte 0 und 1 annehmen kann), ist es zwar möglich, eine lineare Regression durchzuführen – aber nicht empfehlenswert. Hier sind die Gründe:
- Ungültige Vorhersagen: Die lineare Regression kann Werte ausserhalb des Bereichs [0, 1] vorhersagen, was bei Wahrscheinlichkeiten keinen Sinn ergibt.
- Verletzung statistischer Annahmen: Die Fehlerterme sind bei binären Daten nicht normalverteilt und die Varianz ist nicht konstant (Heteroskedastizität).
- Nicht optimale Schätzungen: Die lineare Regression liefert bei binären Daten oft verzerrte und ineffiziente Schätzwerte.
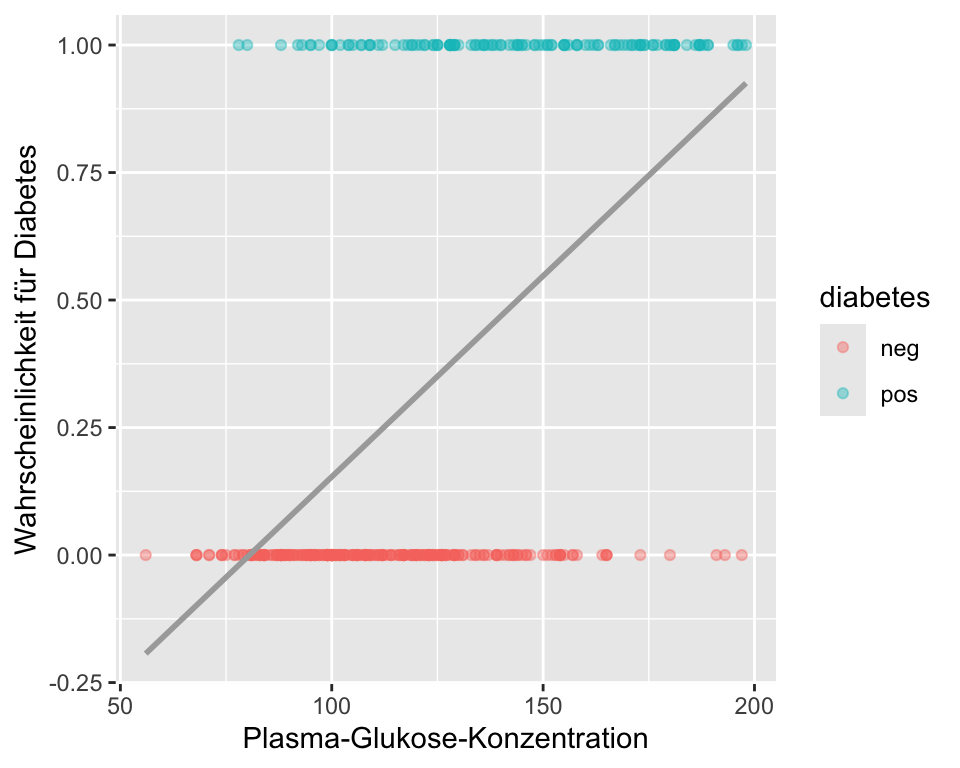
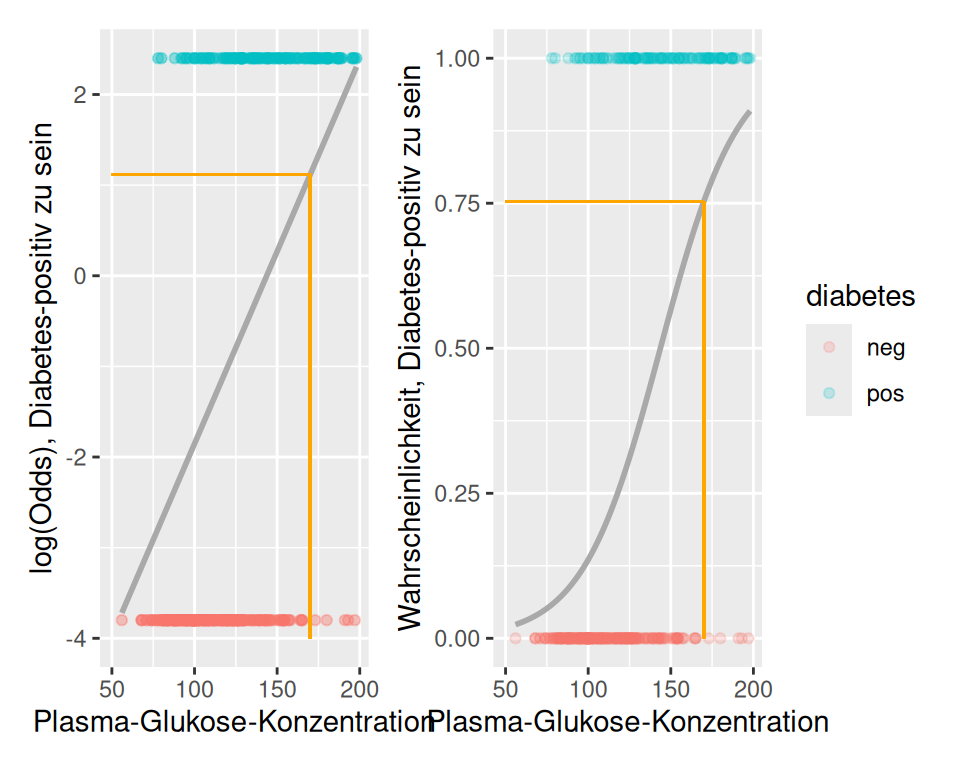
In Abbildung 9.1 sehen wir, dass Personen mit Diabetes (mit 1 kodiert) grundsätzlich höhere Blutzuckerwerte haben als Personen ohne Diabetes. Die Variable glucose scheint also hilfreich zu sein, um den Diabetesstatus, wenn auch nicht perfekt, vorherzusagen. Die graue Gerade ist das statistische Modell, der lineare Prädiktor. In der Grafik wird verdeutlicht, dass sich eine lineare Regression nicht eignet, um die Wahrscheinlichkeit für Diabetes vorherzusagen. Personen mit tiefer Blutzuckerkonzentration hätten eine negative Wahrscheinlichkeit, Diabetes zu haben. Personen mit einer Konzentration von \(>220\) hätten eine Wahrscheinlichkeit \(>1\) Diabetes zu haben. Eine Wahrscheinlichkeit muss aber per Definition im Intervall \([0; 1]\) liegen.
Der Wertebereich der zu modellierenden abhängigen Variablen in einer linearen Regression ist in der Regel nicht beschränkt (theoretisch von \(-\infty\) bis \(\infty\)), Wahrscheinlichkeiten aber sind durch 0 und 1 begrenzt. Wenn man statt der Wahrscheinlichkeit die Odds \(O_i\) modelliert, dann erhält man Werte im Intervall \([0; \infty)\). Wenn man zusätzlich noch den Logarithmus nimmt, also die \(\log Odds_i:=\logit(\pi_i)\) modelliert, dann erhält man Werte im Intervall \((-\infty; \infty)\), weil \(\log(0) = -\infty\) und \(\log(\infty) = \infty\). \(\logit(\pi)\) ist dann nicht beschränkt!
Die folgende Grafik zeigt nun die lineare Regression für \(\logit(\pi)\) auf Blutzucker:
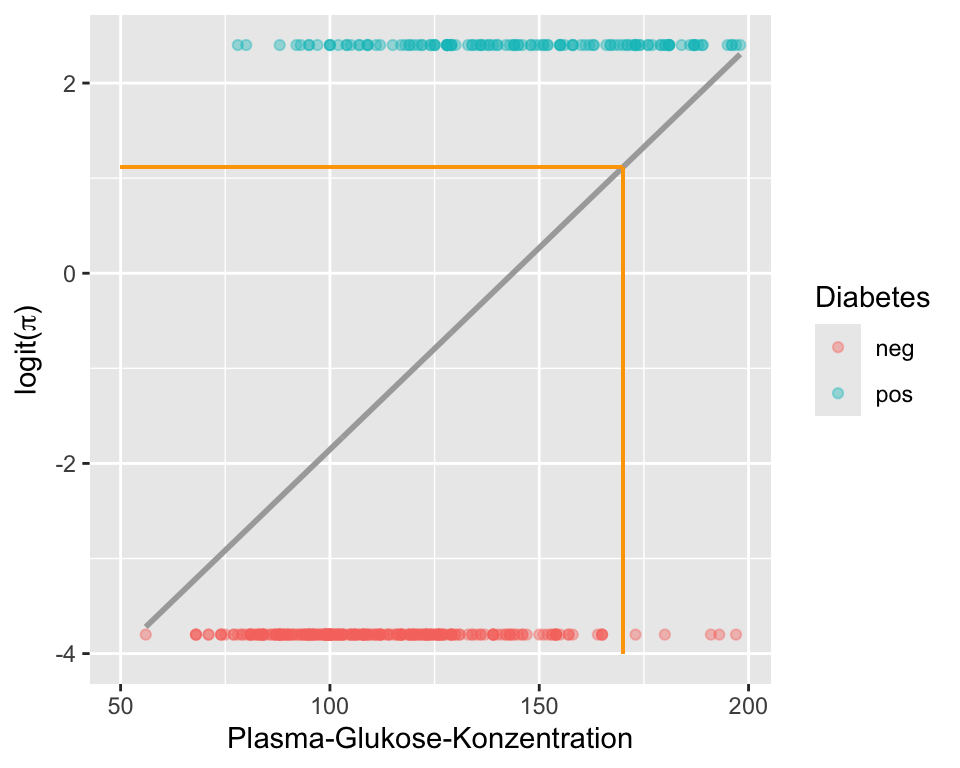
Auf den ersten Blick unterscheiden sich Abbildung 9.1 und Abbildung 9.2 kaum. Der einzige aber entscheidende Unterschied ist, dass die y-Achse dieses Mal die \(\logit(\pi)\) für Diabetes repräsentiert. Wir erhalten durch Exponieren und Umrechnen die Wahrscheinlichkeit, dass bei einer gegebenen Blutzuckerkonzentration ein Diabetes vorliegt. Nehmen wir einen Blutzuckerwert von 170 (orange Linie). Für diesen Wert prognostiziert das Modell \(\logit(\pi) = 1.116\). Somit sind die Odds für Diabetes bei einer Blutzuckerkonzentration von 170 \(\exp(1.116) = 3.0526\). Diese Odds können wir in eine Wahrscheinlichkeit umrechnen,
\[ \hat{\pi} = \frac{\hat{O}}{1+\hat{O}} = \frac{3.0526}{1+3.0526} = 0.7532. \]
Wiederholen Sie diese Rechnung für ein paar andere Blutzuckerwerte und Sie werden merken, dass die Wahrscheinlichkeit immer zwischen 0 und 1 liegt (dazu muss man die \(\logit(\pi_i)\) von Auge schätzen, weil wir ja die Regressionskoeffizienten noch nicht kennen).
Mit dem Computer kann man dies für alle beliebigen Blutzuckerwerte durchrechnen und eine neue Grafik mit den Blutzuckerwerten auf der x-Achse und der Wahrscheinlichkeit \(\pi\) für Diabetes auf der y-Achse erstellen:
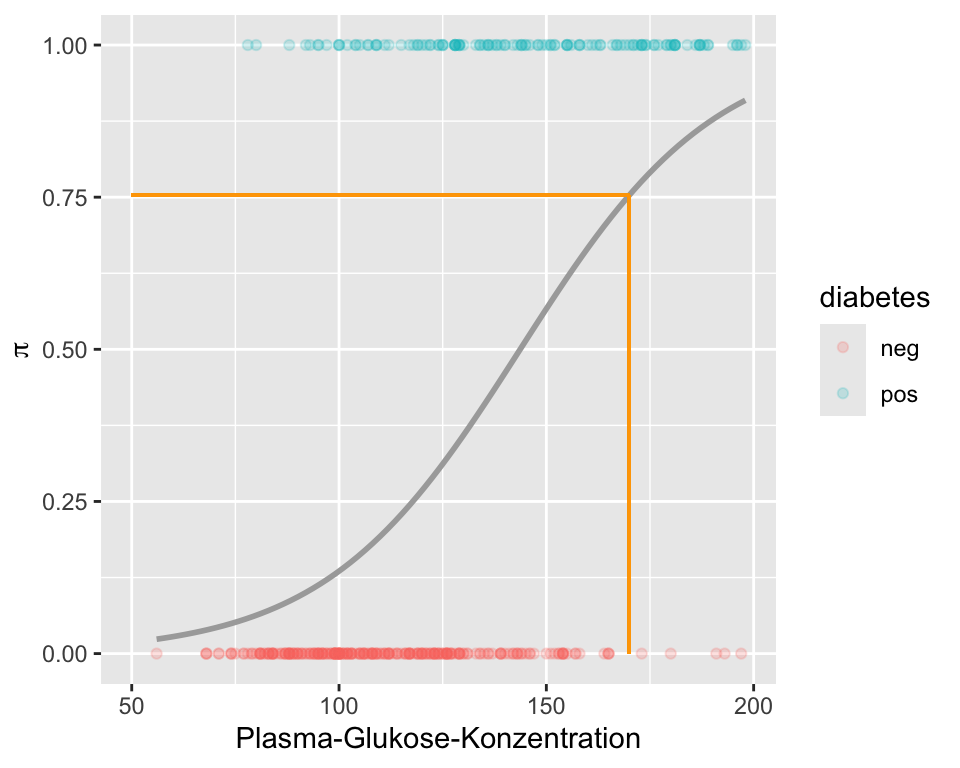
In Abbildung 9.3 sehen wir den logistischen (nicht linearen) Zusammenhang zwischen Blutzucker und der Wahrscheinlichkeit für Diabetes. Fazit: Eine lineare Regression ist nicht optimal, um die Wahrscheinlichkeit für ein Ereignis zu modellieren.
9.5 Einfache logistische Regression
Die logistische Regression ist ein Modell zur Analyse binärer abhängiger Variablen, bei denen die Zielgrösse typischerweise nur zwei Ausprägungen hat (z. B. Erfolg/Misserfolg). Anders als bei der linearen Regression wird hier nicht direkt der Erwartungswert der Zielvariable modelliert, sondern dessen Transformation.
9.5.1 Verteilung
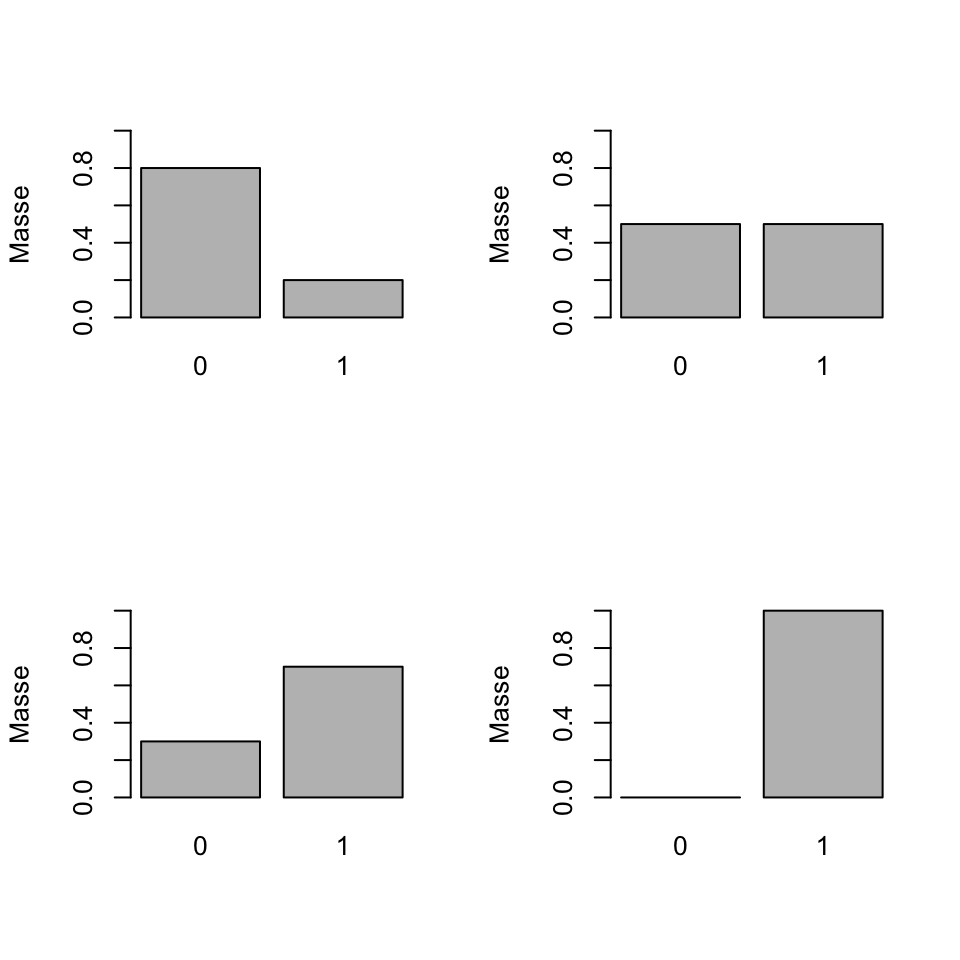
Die Verteilung der \(Y_i\) ist binomial mit Parametern \(\pi_i\) und \(n=1\) (Bernoulli-Verteilung). Wir notieren \[ Y_i\sim \mathcal{B}(n=1,\pi_i) \]
Die Binomialverteilung hat für den Spezialfall einer einzelnen Beobachtung (Bernoulli) die Wahrscheinlichkeitsmasse \(p(y_i) = \pi_i^{y_i} (1 - \pi_i)^{1 - y_i}\), was äquivalent ist zur Aussage: \(Y_i \in \{0,1\}\) mit \(\pi_i = \Pr(Y_i = 1)\) und \(1-\pi_i = \Pr(Y_i = 0)\).
Abbildung Abbildung 9.4 zeigt Bernoulli-Verteilungen für verschiedene \(\pi\).
9.5.2 Erwartungswert
Sei \(X\) eine diskrete Zufallsvariable mit Werten \(x_1, \dots,x_k\) und Wahrscheinlichkeitsmasse \(p(x)\). Der Erwartungswert von \(X\) ist der Mittelwert der möglichen Werte, wobei jede Ausprägung entsprechend ihrer Wahrscheinlichkeit gewichtet wird.
\[\begin{equation} \label{eq:ExpDisc} E(X) = \sum_{i=1}^k x_i\, p(x_i). \end{equation}\]
Für den Spezialfall \(X \sim \mathcal{B}(1,\pi)\) (Bernoulli-Verteilung mit Parameter \(\pi\)) ergibt sich: \[ E(X) = 0 \cdot (1 - \pi) + 1 \cdot \pi = \pi \]
9.5.3 Link Funktion
Der Erwartungswert einer binomialverteilten Variable \(Y\) mit \(n=1\) ist also \(E(Y)=\pi\).
Dieser Erwartungswert (hier eine Wahrscheinlichkeit) soll nun so transformiert werden, dass er nicht mehr beschränkt ist, d.h. der lineare Prädiktor sollte dann alle Werte zwischen \(-\infty\) und \(+\infty\) annehmen können. Dazu müssen wir die logit- und die logistische Funktion einführen. Diese beiden Funktionen sind zentral für das Verständnis einer logistischen Regression.
Logit und Logistische Funktion
\[\text{logit}(x):[0,1]\rightarrow \mathbb{R},\quad x \mapsto \log\frac{x}{1-x} \]
\[\text{logistic}(x): \mathbb{R} \rightarrow [0,1],\quad x \mapsto \frac{\exp(x)}{\exp(x)+1} \]
Die beiden wichtigen Funktionen sind in der Abbildung Abbildung 9.5 dargestellt.
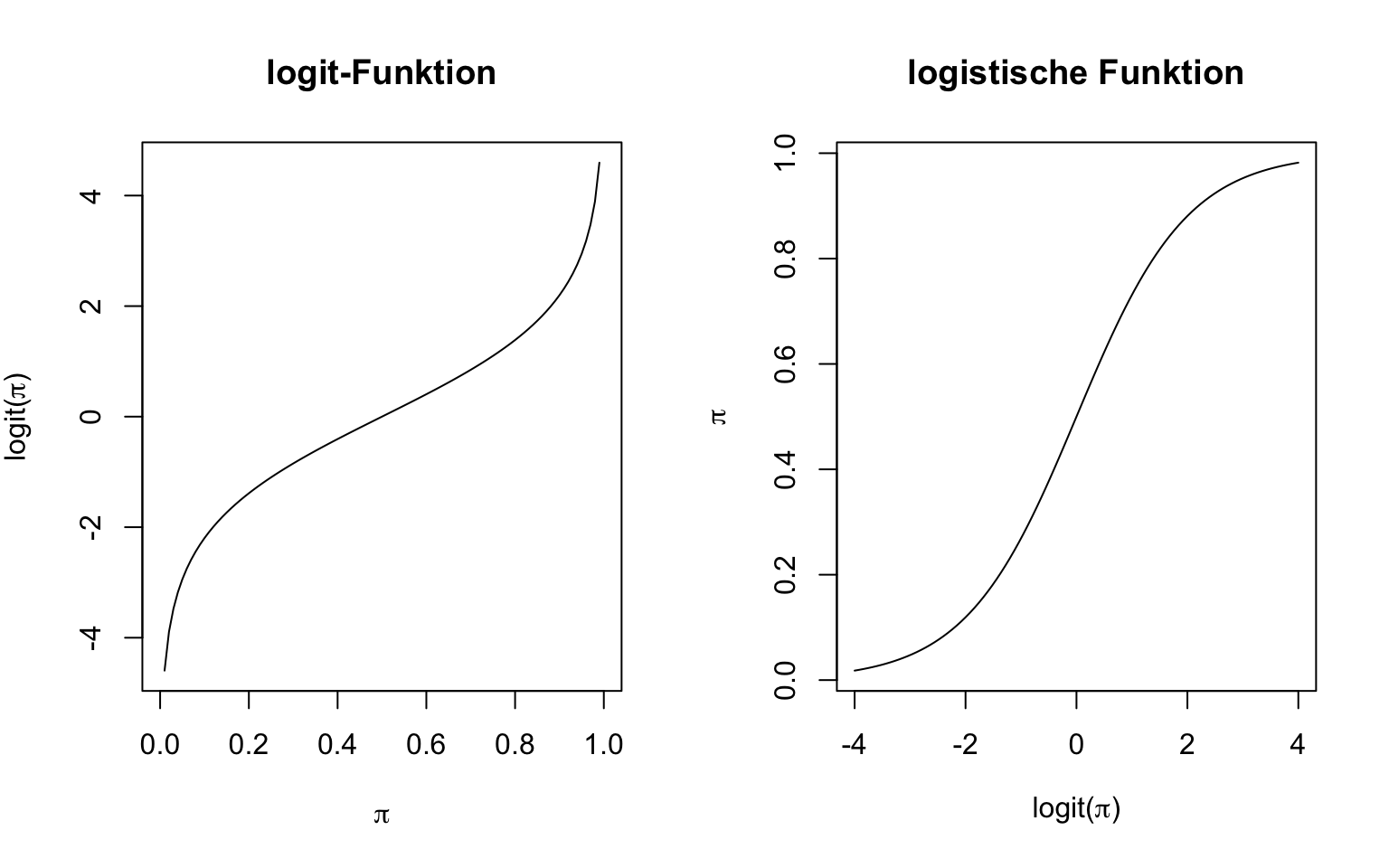
Da der Erwartungswert \(E(Y)=\pi\) zwischen 0 und 1 liegt, wird dieser über die logit-Funktion transformiert:
\[ \text{logit}(\pi) = \log\left(\frac{\pi}{1 - \pi}\right) = \eta \]
Somit wird der transformierte Erwartungswert (der Logit von \(\pi\)) als linearer Prädiktor \(\eta\) dargestellt. Man nennt diese Transformation Link-Funktion. Angewandt auf den Erwartungswert haben wir dann für den linearen Prädiktor
\[ \logit\, \pi_i=\log Odds_i=\log\frac{\pi_i}{1-\pi_i}=\eta_i= \beta_0 + \beta_1x_i, \]
und schreiben sehr oft kurz für eine einfache logistische Regression:
Einfache logistische Regression
\[ \boxed{\logit(\pi_i)=\beta_0 + \beta_1x_i} \tag{9.1}\]
Deterministischer und stochastischer Teil eines Modells
(Lineare) Modelle beinhalten einen deterministischen Teil (der lineare Prädiktor) und einen stochastischen Teil (die Wahrscheinlichkeitsverteilung). In der logistischen Regression nehmen wir die Binomialverteilung (stochastischer Teil) in Equation 9.1 oft stillschweigend an und schreiben nur den linearen Prädiktor.
9.5.4 Rückblick lineare Regression
Zum Vergleich noch einmal die einfache lineare Regression, das Modell war \[Y_i=\beta_0 + \beta_1x_i+\epsilon_i\] mit \(\epsilon_i\sim \mathcal{N}(\mu,\sigma^2)\). Dort war die Verteilung die Normalverteilung und die Link-Funktion war die Identität (keine Transformation des Erwartungswerts nötig),
\[ Y_i\sim \mathcal{N}(\mu_i,\sigma^2),\quad \quad E(Y_i)=\mu_i=\beta_0 + \beta_1x_i. \]
9.5.5 Interpretation
Der Parameter \(\beta_1\) in Equation 9.1 ist zu interpretieren als der Unterschied in Logits für zwei Populationen, die sich auf \(x\) um eine Einheit unterscheiden. Das ist analog zur linearen Regression, da die Logit-Skala ebenfalls ein Kontinuum darstellt. Zusätzlich lässt sich \(\exp(\beta_1)\) als Odds Ratio interpretieren: Es gibt an, um welchen Faktor sich die Odds (also das Verhältnis von Erfolgs- zu Misserfolgswahrscheinlichkeit) verändern, wenn sich \(x\) um eine Einheit erhöht. Ein Wert von \(\exp(\beta_1)>1\) bedeutet, dass die Erfolgswahrscheinlichkeit mit steigendem \(x\) zunimmt, während ein Wert kleiner als 1 auf eine abnehmende Erfolgswahrscheinlichkeit hinweist.
Fassen wir die Unterschiede zum linearen Modell nochmal zusammen:
9.5.6 Lineare vs. Logistische Regression
| Model | Lineare Regression | Logistische Regression | |
|---|---|---|---|
| Verteilung der Zielvariable | Normalverteilung: \(Y \sim \mathcal{N}(\mu, \sigma^2)\) | Bernoulli-Verteilung: \(Y \in \{0,1\},\ \pi = P(Y=1)\) | |
| Erwartungswert | \(E(Y) = \mu\) | \(E(Y) = \pi\) | |
| Linearer Prädiktor | \(\mu = \beta_0 + \beta_1 x\) | \(\eta = \beta_0 + \beta_1 x\) | |
| Transformation (Link-Funktion) | Identität: \(\mu = \eta\) | Logit: \(\text{logit}(\pi) = \log\left(\frac{\pi}{1 - \pi}\right) = \eta\) | |
| Interpretation von \(\beta_1\) | Änderung des Erwartungswerts \(E(Y)\) pro Einheit \(x\) | Änderung der Log-Odds von \(Y=1\) pro Einheit \(x\) | |
| Interpretation von \(\exp(\beta_1)\) | – | Multiplikativer Faktor für die Odds: \(\exp(\beta_1)\) ist die Odds Ratio für eine Einheit mehr in \(x\) |
9.5.7 Wahrscheinlichkeit
Die Wahrscheinlichkeit für das Ereignis erhalten wir dann mit der Umkehrfunktion der \(\logit\)-Funktion, der logistischen Funktion, die auf den linearen Prädiktor \(\eta_i=\beta_0+\beta_1x_i\) angewandt wird,
\[ \boxed{\pi_i=\frac{O_i}{1+O_i}=\frac{\exp(\logit(\pi_i))}{1+\exp(\logit(\pi_i))}=\frac{\exp(\eta_i)}{1+\exp(\eta_i)}}. \tag{9.2}\]
9.5.8 Dichotomer Prädiktor: Schwangerschaft und Diabetes
Wir verwenden weiterhin den Diabetes-Datensatz und untersuchen nun, ob es einen Zusammenhang gibt zwischen Diabetes und ob eine Frau bereits eine Schwangerschaft hatte oder nicht. Für dieses Beispiel lässt sich eine Vierfeldertabelle darstellen:
Diabetes
Pregnant neg pos
No 37 19
Yes 225 111Anhand der Vierfeldertabelle kann man die Wahrscheinlichkeiten für das Ereignis und Nicht-Ereignis bei Kondition pregnant und not pregnant schätzen:
Die geschätzten Wahrscheinlichkeiten sind
\[ \hat{\pi}_{pregnant} = \frac{111}{111+225} = 0.3303571, \] und \[ \hat{\pi}_{not.pregnant} = \frac{19}{19+37} = 0.3392857 \]
Die geschätzten Odds sind \[ \hat{O}_{pregnant} = \frac{111}{225} = 0.493, \] \[ \hat{O}_{not.pregnant} = \frac{19}{37} = 0.514, \]
und somit die geschätzte Odds Ratio \[ \widehat{OR} = \frac{0.493}{0.514} = 0.96. \]
Wir schauen uns nun an, was die logistische Regression mit den gleichen Variablen für einen Output liefert. Für logistische Regressionen brauchen wir in R die Funktion glm(), was für generalized linear models steht. Weil diese Modelle eben verallgemeinert sind, muss man zusätzlich die Verteilung und die Link-Funktion angeben, welche gebraucht wird. Weil es in diesem Fall um eine binäre abhängige Variable geht, verwenden wir die Binomialverteilung. Wir tun das mit dem Argument family = binomial(link="logit"). Der logit-link ist bei Binomialveteilung zwar defaultmässig eingestellt, family = binomial() würde auch genügen. Es ist aber immer besser, am Anfang beides explizit darzustellen. Die Syntax für die Erstellung der Modelle ist dann analog zur linearen Regression:
# Einfache logistische Regression mit glm()
m.glm1 <- glm(diabetes ~ pregnant_bin, data = diabetes, family = binomial(link="logit")) Wir schauen das angepasste Modell an und konzentrieren uns auf die geschätzten Regressionskoeffizienten:
summary(m.glm1)$coef Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.66647893 0.2822385 -2.3614032 0.01820593
pregnant_binYes -0.04009127 0.3051426 -0.1313853 0.89547049\(\beta_0\) (das Intercept) steht für die \(\logit\) für Diabetes, wenn die unabhängige Variable den Wert 0 (oder die Referenzkategorie “No”) annimmt. Wie bei der linearen Regression wird die Variable pregnant_bin mit 0 und 1 codiert (dummy coding). Also sind \(\hat{\beta}_0\) die \(\logit\) für Diabetes, wenn eine Frau noch keine Schwangerschaft hatte. Wenn wir dies exponieren, dann erhalten wir 0.5135135. Wir können mit den Angaben aus der Vierfeldertabelle feststellen, dass dies korrekt ist. Mit der logistischen Funktion (Equation 9.2) können wir die \(\pi_i\) für beide Gruppen abschätzen:
Wenn nun die Variable pregnant_bin den Wert “No” annimmt, haben wir:
\[ \begin{align} \logit(\hat{\pi})_{not.pregnant}&=\hat{\beta}_0= -0.6664789\\ \hat{O}_{not.pregnant}&=\exp(\hat{\beta}_0)= 0.5135135\\ \hat{\pi}_{non.pregnant}&=\frac{\exp(\hat{\beta}_0)}{1+\exp(\hat{\beta}_0)}=0.3392857 \end{align} \]
Wenn nun die Variable pregnant_bin den Wert “Yes” annimmt, haben wir:
\[ \begin{align} \logit(\hat{\pi})_{pregnant} &= \hat{\beta}_0+\hat{\beta}_1= -0.7065702\\ \hat{O}_{pregnant}& = \exp(\hat{\beta}_0+\hat{\beta}_1)= 0.4933333\\ \hat{\pi}_{pregnant}&=\frac{\exp(\hat{\beta}_0+\hat{\beta}_1)}{1+\exp(\hat{\beta}_0+\hat{\beta}_1)}=0.3303571 \end{align} \]
Dies stimmt natürlich auch wieder überein mit den direkten Berechnungen in der Vierfeldertafel.
Mit der predict() Funktion können wir uns die geschätzten \(\logit\) und \(\pi\) direkt ausgeben lassen. Defaultmässig ist die Vorhersage auf dem linearen Prädiktor, mit Argument type="response" bekommen wir Wahrscheinlichkeits-Vorhersagen:
predict(m.glm1,newdata=data.frame(pregnant_bin=c("No","Yes"))) 1 2
-0.6664789 -0.7065702 predict(m.glm1,newdata=data.frame(pregnant_bin=c("No","Yes")),type="response") 1 2
0.3392857 0.3303571 Was bedeutet nun \(\hat{\beta}_1\)? Im logistischen Modell ist die Steigung als \[\beta_1=\logit_{preg}-\logit_{nonpreg}=\log\frac{O_{preg}}{O_{nonpreg}}=\log(OR)\] zu interpretieren. Somit ist \(\hat{\beta}_1=-0.0400913\) der geschätzte Unterschied auf \(\logit\)-Skala und \(\exp(\hat{\beta}_1)=\exp(-0.0400913)=0.9607018\) die geschätzte Odds Ratio, was wiederum mit den Berechnungen auf Basis der Vierfeldertabelle übereinstimmt.
9.5.9 Intervallschätzung
Wie bei der linearen Regression können wir mit dem Befehl confint() die 95% Konfidenzintervalle der Regressionskoeffizienten abrufen:
confint(m.glm1) 2.5 % 97.5 %
(Intercept) -1.2398480 -0.1261716
pregnant_binYes -0.6274561 0.5748354Die Schranken sind hier auf \(\log(OR)\)-Skala. Für eine inhaltlich sinnvolle Interpretation ist es daher oft empfehlenswert, die Grenzen des Intervalls zu exponieren, um Konfidenzintervalle für \(OR\) zu erhalten.
exp(confint(m.glm1)) 2.5 % 97.5 %
(Intercept) 0.2894282 0.8814635
pregnant_binYes 0.5339484 1.7768380Wir sehen, dass das 95% Konfidenzintervall für das \(OR\) von 0.5339484 bis 1.776838 geht. Wir können also zu 95% darauf vertrauen, dass das wahre \(OR\) von diesem Intervall überdeckt wird. Da dieses Intervall stark mit dem Nullwert (welcher bei \(OR=1\) oder \(\log(OR)=0\) liegt) überlappt, besteht keine Evidenz gegen \(H_0\). Dies ist auch dem hohen P-Wert im Output zu entnehmen (\(p=0.8954705\)). Der diesbezügliche \(z\)-Test ist ein Wald-Test; diesen sowie die hier berechneten Likelihood-Intervalle führen wir in Section 9.7.4 ein.
Eine Schwangerschaft scheint also die Odds für Diabetes nicht zu erhöhen. (Inhaltliche Anmerkung: Dies gilt nur für die Variable pregnant_bin, jedoch nicht für die Variable pregnant.)
Mit parameters() aus dem gleichnamigen Packet können wir uns direkt die exponierten Koeffizienten mit Intervallschätzung und Tests herausgeben lassen:
parameters::parameters(m.glm1,exponentiate=TRUE,digits=3)Parameter | Odds Ratio | SE | 95% CI | z | p
-------------------------------------------------------------------------
(Intercept) | 0.514 | 0.145 | [0.289, 0.881] | -2.361 | 0.018
pregnant bin [Yes] | 0.961 | 0.293 | [0.534, 1.777] | -0.131 | 0.8959.5.10 Exkurs: Risk Ratios versus Odds Ratios
Eine Einschränkung der logistischen Regression ist, dass die Effekte (log) Odds Ratios und nicht (log) Risk Ratios darstellen. Das ist dann problematisch, wenn ausdrücklich Risiko-Verhältnisse gewünscht werden, da sich Chancenverhältnisse von Risiko-Verhältnissen stark unterscheiden können, insbesondere wenn das Ereignis häufig ist. Bei seltenem Ereignis ist \(OR\) eine gute Schätzung für das Risk Ratio. Eine Möglichkeit, Risk Ratios als Effekte zu erhalten, ist das Log-Binomiale Modell.
In diesem Modell wird jetzt der \(\log\) als Link-Funktion an Stelle von \(\logit\) gebraucht mit der Konsequenz, dass \(\beta_1\) ein \(\log\) Risk Ratio und \(\exp(\beta_1)\) ein Risk Ratio darstellt.
Wie Sie aus Chapter 8 wissen, kann man obige 2x2 Tabelle mit Hilfe der riskratio() Funktion aus dem Paket epitools analysieren. Der Output sieht wie folgt aus (es wird nur ein Teil davon gezeigt):
tab Diabetes
Pregnant neg pos
No 37 19
Yes 225 111epitools::riskratio(tab,method="wald")$measure risk ratio with 95% C.I.
Pregnant estimate lower upper
No 1.0000000 NA NA
Yes 0.9736842 0.6553428 1.446664Das Risk Ratio beträgt 0.974, mit einem 95% CI von [0.655; 1.447].
riskratio() entspricht einem Log-Binomial Modell mit zweiwertigem Prädiktor:
m.logBin<-glm(diabetes~pregnant_bin,family=binomial(link="log"),data=diabetes)
parameters::parameters(m.logBin,exponentiate=TRUE,ci_method="wald",digits=3) Parameter | Risk Ratio | SE | 95% CI | z | p
--------------------------------------------------------------------------
(Intercept) | 0.339 | 0.063 | [0.235, 0.489] | -5.796 | < .001
pregnant bin [Yes] | 0.974 | 0.197 | [0.655, 1.447] | -0.132 | 0.895 Der \(\log\)-Link hat aber den Nachteil, dass er Wahrscheinlichkeiten nur auf \(\mathcal{R^+}\) statt auf \(\mathcal{R}\) abbildet. Bei diesen Modellen gibt es oft Konvergenzprobleme, die sind bei Log-binomialen Modellen oft auf die Schwierigkeit zurückführen, die Wahrscheinlichkeiten im Bereich von [0, 1] zu halten, sowie auf die inhärente Komplexität der Likelihood-Oberfläche, insbesondere bei bestimmten Datenstrukturen.
Ein weitere Methode, um als Effektgrössen Risk Ratios zu bekommen, ist die Robuste Poisson Regression, auf die wir hier an dieses Stelle nicht eingehen.
9.5.11 Kontinuierlicher Prädiktor: Blutzucker und Diabetes
Wir greifen das Beispiel “Blutzucker und Diabetes” aus Section 9.4 wieder auf. Anhand dieses neuen Beispiels wird gezeigt, wie eine einfache logistische Regression mit einer quantitativen Prädiktorvariable interpretiert wird. Das Modell kann nun geschrieben werden als
\[ \logit(\pi_i) = \beta_0+\beta_1 glucose_i. \]
Da bei einer kontinuierlichen Eingangsgrösse eine Darstellung als Vierfeldertabelle nicht mehr möglich ist, passen wir direkt ein Modell an
m.glm2 <- glm(diabetes ~ glucose, data = diabetes, family = binomial())und schauen uns die Punktschätzung, Standardfehler, Konfidenzintervall, \(z\)-Werte und \(p\)-Werte an. In die Theorie bezüglich Tests und Intervallschätzung in der logistischen Regression werden wir in Section 9.7.4 eingehen.
summary(m.glm2)$coef Estimate Std. Error z value Pr(>|z|)
(Intercept) -6.09552139 0.629787038 -9.678703 3.713993e-22
glucose 0.04242099 0.004760623 8.910805 5.066328e-19confint(m.glm2) 2.5 % 97.5 %
(Intercept) -7.38670938 -4.91195171
glucose 0.03346065 0.05216953von Hand zusammengefasst,
cbind(summary(m.glm2)$coef,confint(m.glm2)) Estimate Std. Error z value Pr(>|z|) 2.5 %
(Intercept) -6.09552139 0.629787038 -9.678703 3.713993e-22 -7.38670938
glucose 0.04242099 0.004760623 8.910805 5.066328e-19 0.03346065
97.5 %
(Intercept) -4.91195171
glucose 0.05216953oder einfacher mit parameters() auf \(logit\)-Skala:
parameters::parameters(m.glm2,exponentiate=FALSE) ##DefaultParameter | Log-Odds | SE | 95% CI | z | p
-------------------------------------------------------------------
(Intercept) | -6.10 | 0.63 | [-7.39, -4.91] | -9.68 | < .001
glucose | 0.04 | 4.76e-03 | [ 0.03, 0.05] | 8.91 | < .001und auf \(OR\)-Skala:
parameters::parameters(m.glm2,exponentiate=TRUE)Parameter | Odds Ratio | SE | 95% CI | z | p
-------------------------------------------------------------------
(Intercept) | 2.25e-03 | 1.42e-03 | [0.00, 0.01] | -9.68 | < .001
glucose | 1.04 | 4.97e-03 | [1.03, 1.05] | 8.91 | < .001\(\hat{\beta}_0\) ist das geschätzte \(\logit\) für Diabetes, bei einem Blutzucker von 0 mg/dl. Es macht inhaltlich keinen Sinn, den Wert zu interpretieren. Daher sind wir auch nicht beeindruckt, dass sich dieser \(\logit\) statistisch signifikant von 0, bzw. die Odds statistisch signifikant von 1 unterscheiden. Meistens interessiert dieses Intercept (die Lage des Modells), nicht.
\(\hat{\beta}_1\) ist der geschätzte Effekt von Blutzucker auf Diabetes, also das \(\log(OR)\). Pro zusätzliches Milligramm Zucker pro Deziliter Blut steigt (das Vorzeichen ist positiv) das \(\logit\) für Diabetes um 0.042421. Anhand des sehr kleinen \(p\)–Wertes wissen wir bereits, dass es einen statistisch signifikanten Zusammenhang zwischen glucose und diabetes gibt. Das \(OR\) von 1.0433336 unterscheidet sich also statistisch signifikant von 1. Diese Grösse ist der Effekt pro Milligramm Zucker pro Deziliter Blut.
Bei einem Unterschied von 10mg/dl beträgt das \(OR\) also schon 1.528 (Versuchen Sie, dies aufgrund der Linearität nachzuvollziehen mit \(\exp(10x)=(\exp(x))^{10})\).
9.5.12 Vorhersage
Anhand der geschätzten Regressionskoeffizienten können wir nun die Regressionsgleichung benutzen, um die Odds für Diabetes bei einer bestimmten Blutzuckerkonzentration, z.B. 170 mg/dl, zu schätzen:
\[ \logit(\hat{\pi})_{gluc=170} = -6.0955214 + 0.042421 \times 170 = 1.1160464, \]
\[ \hat{O}_{gluc=170} = \exp(-6.0955214 + 0.042421 \times 170) = 3.0527608, \]
und somit
\[ \hat{\pi}_{gluc=170} = \frac{\exp(-6.0955214 + 0.042421 \times 170)}{1+\exp(-6.0955214 + 0.042421 \times 170)} = 0.7532546 \]
Es handelt sich dabei genau um den Wert des Einführungsbeispiels aus Section 9.4:
9.6 Multiple logistische Regression
Wie bei der linearen Regression, kann man auch bei einer logistischen Regression zusätzliche Prädiktorvariablen in das Model einfliessen lassen, um entweder
- interessierende Effekte für potentielle Confounder zu kontrollieren
- um ein optimales Model zu entwickeln.
- Effekte bedingt auf andere Eingangsgrössen zu quantifizieren.
Für \(m\) unabhängige Variablen lautet das Modell (der lineare Prädiktor) dann
\[ \boxed{\logit(\pi_i) = \beta_0 + \beta_1x_{i1}+\dots+\beta_m x_{im}.} \]
Die wahren \(\beta\)’s werden wie immer geschätzt anhand von Stichprobendaten (Auf die Schätzmethode werden weiter unten eingehen):
\[ \logit(\hat{\pi}_i) = \hat{\beta}_0 + \hat{\beta}_1 x_{i1}+\dots+\hat{\beta}_m x_{im}, \]
\[ \hat{O_i} = \exp(\hat{\beta}_0 + \hat{\beta}_1 x_{i1}+\dots+\hat{\beta}_m x_{im}), \]
und folglich
\[ \hat{\pi}_i = \frac{\exp(\hat{\beta}_0 + \hat{\beta}_1 x_{i1}+\dots+\hat{\beta}_m x_{im})}{1+\exp(\hat{\beta}_0 + \hat{\beta}_1 x_{i1}+\dots+\hat{\beta}_m x_{im})}. \]
Wir erstellen zuerst ein multiples Modell mit allen Prädiktoren und schauen uns den Output an:
# Erstellen des multiplen logistischen Regressionsmodell
m.glmF <- glm(diabetes ~ pregnant_bin + glucose + pressure +
triceps + insulin + mass + pedigree + age,
data = diabetes, family = binomial())
round(summary(m.glmF)$coef,3) Estimate Std. Error z value Pr(>|z|)
(Intercept) -10.167 1.307 -7.776 0.000
pregnant_binYes 0.002 0.422 0.005 0.996
glucose 0.038 0.006 6.603 0.000
pressure -0.001 0.012 -0.091 0.927
triceps 0.012 0.017 0.680 0.496
insulin -0.001 0.001 -0.710 0.478
mass 0.067 0.028 2.409 0.016
pedigree 1.079 0.423 2.551 0.011
age 0.052 0.015 3.506 0.000Mit Ausnahme vom Intercept (\(\logit\) für Diabetes, wenn alle Eingangsgrössen 0) sehen wir für jede der acht unabhängigen Variablen einen Effekt mit geschätztem \(\log(OR)\), Standardfehler, \(z\)-Statistik und \(p\)-Wert für den test der jeweiligen \(H_0:\beta_k=0, k=1,\dots,8\).
Interessieren wir uns beispielsweise für das \(OR\) bzgl. glucose, kann der entsprechende Wert exponiert werden, was ein \(OR\) von 1.0389345 ergibt. Pro zusätzliches Milligramm Zucker pro Deziliter Blut steigen (das Vorzeichen ist positiv) die Odds für Diabetes um diesen Faktor. Dies unter Berücksichtigung aller anderen Prädiktorvariablen, d.h. das ist der Effect von glucuse, der über den Effekt der anderen Eingangsgrössen im Modell hinausgeht. Beachten Sie, dass das OR für glucose im multiplen Modell verschieden ist als im einfachen Modell (1.039 vs. 1.043). Dies, weil im einfachen Modell der Effekt von glucose isoliert, im multiplen Modell jedoch unter Berücksichtigung aller anderen Variablen berechnet wird, für diese kontrolliert wird. Das Gleiche gilt für die Interpretation aller anderen Koeffizienten.
Mit parameters() aus dem Packet parameters kann man sich wieder – alternativ – mit exponentiate=TRUE direkt geschätzte \(OR\), Standardfehler, 95% KI, \(z\)- und \(p\)-Wert herausgeben lassen:
parameters::parameters(m.glmF,exponentiate=TRUE,digits=3)Parameter | Odds Ratio | SE | 95% CI | z | p
------------------------------------------------------------------------------
(Intercept) | 3.840e-05 | 5.021e-05 | [0.000, 0.000] | -7.776 | < .001
pregnant bin [Yes] | 1.002 | 0.423 | [0.445, 2.347] | 0.005 | 0.996
glucose | 1.039 | 0.006 | [1.028, 1.051] | 6.603 | < .001
pressure | 0.999 | 0.012 | [0.976, 1.023] | -0.091 | 0.927
triceps | 1.012 | 0.017 | [0.978, 1.046] | 0.680 | 0.496
insulin | 0.999 | 0.001 | [0.996, 1.002] | -0.710 | 0.478
mass | 1.069 | 0.030 | [1.013, 1.130] | 2.409 | 0.016
pedigree | 2.941 | 1.243 | [1.307, 6.858] | 2.551 | 0.011
age | 1.053 | 0.016 | [1.024, 1.085] | 3.506 | < .0019.6.1 Vorhersage
Was ist die Wahrscheinlichkeit gemäss Modell für einen Diabetes für eine Frau mit den folgenden Werten?
| pregnant_bin | glucose | pressure | triceps | insulin | mass | pedigree | age |
|---|---|---|---|---|---|---|---|
| Yes | 197 | 70 | 45 | 543 | 30.5 | 0.158 | 53 |
Wir setzen als erstes die Koeffizienten sowie die Werte der jeweiligen Prädiktoren in die Regressionsgleichung ein, um den Wert des linearen Prädiktors zu berechnen:
\[ \begin{align} \logit(\hat{\pi}) =& -10.1674594 + 0.0021074+0.0381956\times 197 -0.0010788\times 70\\&+ 0.0116816 \times 45 -9.4250878\times 10^{-4} \times 543+0.0666242 \times 30.5+1.0786763 \times 0.158\\&+ 0.052011 \times 53= 2.2566111 \end{align} \]
Durch Exponieren erhalten wir die Odds:
\[ \hat{O} = \exp(2.2566111) = 9.5506685 \]
Die Wahrscheinlichkeit ist schliesslich
\[ \hat{\pi} = \frac{\exp(2.2566111)}{1+\exp(2.2566111)} = 0.9052193 \]
Eine Frau mit den Werten aus Tabelle 9.1 hat eine Wahrscheinlichkeit von 90.5% für einen Diabetes. Die Werte entsprechen denjenigen der 4. Person im Datensatz. Tatsächlich hat diese Person Diabetes.
| pregnant_bin | glucose | pressure | triceps | insulin | mass | pedigree | age | diabetes |
|---|---|---|---|---|---|---|---|---|
| Yes | 197 | 70 | 45 | 543 | 30.5 | 0.158 | 53 | pos |
Wenn man ein logistisches Modell in R rechnet, dann ist die Vorhersage bzgl. dem linearen Prädiktor und bzgl. der Wahrscheinlichkeit für das Ereignis für jede Person bereits hinterlegt. Mit $linear.predictors und $fitted.values können diese aufgerufen werden.
m.glmF$linear.predictors[4] # Der lineare Prädiktor für die 4. Person 9
2.256611 m.glmF$fitted.values[4] # Die Wahrscheinlichkeit von Diabetes für die 4. Person 9
0.9052193 Die Wahrscheinlichkeit ist dann die logistische Funktion evaluiert beim Wert des linearen Prädiktors \(\eta\),
\[ \hat{\pi}_i=\frac{\exp(\hat{\eta}_i)}{1+\exp(\hat{\eta}_i)}, \]
eta<-m.glmF$linear.predictor[4]
exp(eta)/(1+exp(eta)) 9
0.9052193 Hinweis: die 9 im header kommt davon, dass die Person die ID 9 hat.
9.7 Exkurs: Schätzmethoden
Es gibt drei grundlegende Methoden, um unbekannte Parameter (einer Verteilung) zu schätzen:
- Methode der kleinsten Quadrate
- Momentenmethode
- Maximum Likelihood Methode
Die erste haben wir im Rahmen der linearen Regression schon angetroffen, die zweite wird hier der Vollständigkeit halber aufgeführt, die Maximum Likelihood Methode ist die häufigste und wichtigste Methode.
Ziel dieses Abschnitts ist es, in das Prinzip der Methoden, insbesondere der dritten, der Maximum Likelihood Methode, einzutauchen. Wir wollen ein Gespür dafür entwickeln, wie man aus Daten Schätzer konstruiert.
9.7.1 Methode der kleinsten Quadrate
Diese Methode wurde bereits in der multiplen Regression angewandt. Da sie grundlegend ist, wollen wir sie hier kurz wiederholen. Wir fangen an mit einem grundlegenden Schätzproblem, das Schätzen eines wahren Durchschnitts \(\mu\). Der Kleinste-Quadrate-Schätzer (Least Squares, LS-Schätzer) von \(\mu\) ist der Wert, der die Fehler-Quadratsumme
\[\begin{equation} ss(\mu)=\sum_{i=1}^n(X_i-\mu)^2 \end{equation}\]
minimiert. Aus der Schule erinnern wir uns: Gelöst werden solche Probleme in der Regel, indem man \(ss(\mu)\) nach \(\mu\) ableitet und null setzt,
\[\frac{\text{d} ss}{\text{d} \mu}=-2(\sum_{i=1}^nX_i-n\mu)=0.\]
Daraus folgt für den Schätzer (Variable) und Schätzwert (Zahl):
\[ \hat{\mu}_{LS}=\frac{\sum_{i=1}^nX_i}{n}=\bar{X}, \qquad \hat{\mu}_{LS}=\frac{\sum_{i=1}^nx_i}{n}=\bar{x} \]
Man notiert beide, \(\bar{X}\) und \(\bar{x}\), mit \(\hat{\mu}\). Aus dem Kontext wird meistens klar, ob mit \(\hat{\mu}\) ein Schätzer oder ein Schätzwert gemeint ist.
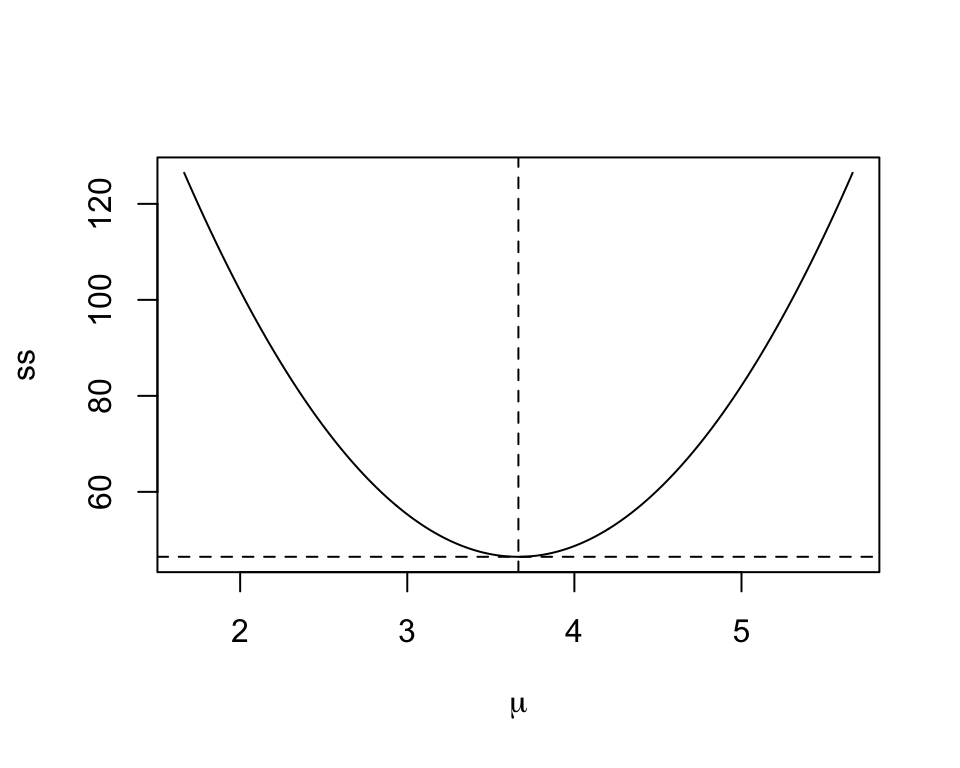
Beispiel: Seien die Daten einer Stichprobe aus \(X\): \(2.08, 3.41, 4.52, 1.7, 4.39, 4.06, 4.17, 6.23, 1.56, 6.53, 2.51, 1.74, 2.57, 4.51, 4.3, 3.38, 2.09, 2.7, 6.45, 4.4\) mit \(\bar{x}=3.665\).
Der Schätzer von \(\mu\) mit minimaler Fehlerquadratsumme ist \(\hat{\mu}_{LS}=\bar{X}\) und der Schätzwert damit \(3.665\). Es gibt keine andere Statistik (d.h. keine andere Grösse, die wir aus den Daten berechnen können), für die die Summe der Abweichungsquadrate \(ss(\mu)\) kleiner ist.
Abbildung Abbildung 9.7 zeigt die Summe der Abweichungsquadrate bei diesen Daten als Funktion von \(\mu\).
Diese Methode wird sehr häufig – wie wir gesehen haben – in der linearen Regression gebraucht. Dort hing der Erwartungswert \(E(Y_i)=\mu_i\) von gesuchten Parametern ab, z.B. den Parametern \(\alpha\) und \(\beta\) in der einfachen lineare Regression (\(Y_i=\alpha+\beta x_i+\epsilon_i\)) also \(E(Y_i)=\mu_i=\alpha+\beta x_i\). Minimiert wird hier die Summe der Fehlerquadrate
\[\sum_{i=1}^n\hat{\epsilon}_i^2=\sum_{i=1}^n (Y_i-\mu_i)^2=\sum_{i=1}^n (Y_i-\alpha-\beta x_i)^2,\] um Schätzer \(\hat{\alpha}\) und \(\hat{\beta}\) für \(\alpha\) und \(\beta\) zu finden.
9.7.2 Momentenmethode
Wir möchten den Therapieerfolg einer neuen Behandlung schätzen und führen zu diesem Zweck die neue Behandlung an 100 Personen durch. Jede Person stellt dabei ein unabhängiges Bernoulli-Experiment dar, welches den Ausgang “Erfolg” oder “Misserfolg” haben kann. Man sagt auch, dass man dann \(n\) Bernoulli Variablen \(X_1,\dots,X_n\) mit unbekanntem Paramteter \(\pi\) hat. Beobachtet wurden nun 37 Erfolge. Wir wollen jetzt einen Schätzer für \(\pi\).
Das Moment der Ordnung \(k\) von \(X\) ist definiert als
\[ m_k:=E(X^k). \]
Die Momentenmethode besteht darin, die \(k\) Momente als Funktionen von \(k\) unbekannten Parametern auszudrücken
\[ \begin{align} E(X)&=g_1(\theta_1,\theta_2,\dots,\theta_k)\\ E(X^2)&=g_2(\theta_1,\theta_2,\dots,\theta_k)\\ &\vdots\\ E(X^k)&=g_k(\theta_1,\theta_2,\dots,\theta_k) \end{align} \]
Diese \(k\) Gleichungen werden dann nach den \(k\) Parametern aufgelöst. Solche Probleme kennen wir vielleicht noch aus der Schulzeit. Hier haben wir nur einen unbekannten Parameter, \(\pi\), brauchen also nur das erste Moment
\[ E(X)=g(\pi) \]
Der Erwartungswert einer \(\mathcal{B}(\pi,1)\) verteilten Variablen ist bekannterweise schon das erste Moment, also haben wir
\[g(\pi)=\pi.\]
Wir ersetzen nun das theoretische Moment durch das Stichprobenmoment. Der Schätzer und Schätzwert sind dann
\[ \hat{\pi}_{MM}=\frac{1}{n}\sum_{i=1}^n X_i, \qquad \hat{\pi}_{MM}=\frac{1}{n}\sum_{i=1}^n x_i=\frac{37}{100} \]
Die geschätzte Wahrscheinlichkeit (Punktschätzung), dass die Therapie erfolgreich ist, ist gemäss der Momentenmethode 0.37. Wir wissen bereits, dass bei Wiederholung der Studie die neue Schätzung aufgrund leicht anderer Beobachtungen nicht zwingend wieder 37% ergeben wird (Stichprobenvariation). Der Schätzer hat ja selber eine Verteilung, über die man dann Konfidenzintervalle konstruieren kann (siehe Section 8.4). Eine Methode zur Konstruktion von Konfidenzintervallen werden wir bei der Maximum Likelihood Methode sehen.
9.7.3 Maximum Likelihood Methode
Eine wichtige Grösse – für viele sogar die fundamentalste Grösse in der Statistik – ist die Likelihood. Die Maximum-Likelihood-Methode (ML) ist die wichtigste Methode zur Schätzung unbekannter Modellparameter aus Daten. Sie erfordert jedoch Kenntnisse über die Verteilung der Daten.
9.7.3.1 Likelihood-Funktion
Die Wahrscheinlichkeitsdichte (oder -masse) \(p(x;\theta)\) beschreibt die Verteilung der Variable \(X\) für fixierten Parameter \(\theta\). Das Ziel ist nun die Inferenz bezüglich \(\theta\) bei vorliegenden Daten \(x\). Im obigen Beispiel war das die Inferenz bezüglich \(\pi\) bei vorliegenden \(x=37\) aus \(n=100\).
Eine zentrale Rolle spielt nun die Likelihood-Funktion
\[ \boxed{L(\theta;x)=p(x;\theta)} \]
gesehen als Funktion von \(\theta\) bei vorliegendem \(x\). Wir schreiben dafür in der Folge nur noch kurz \(L(\theta)\).
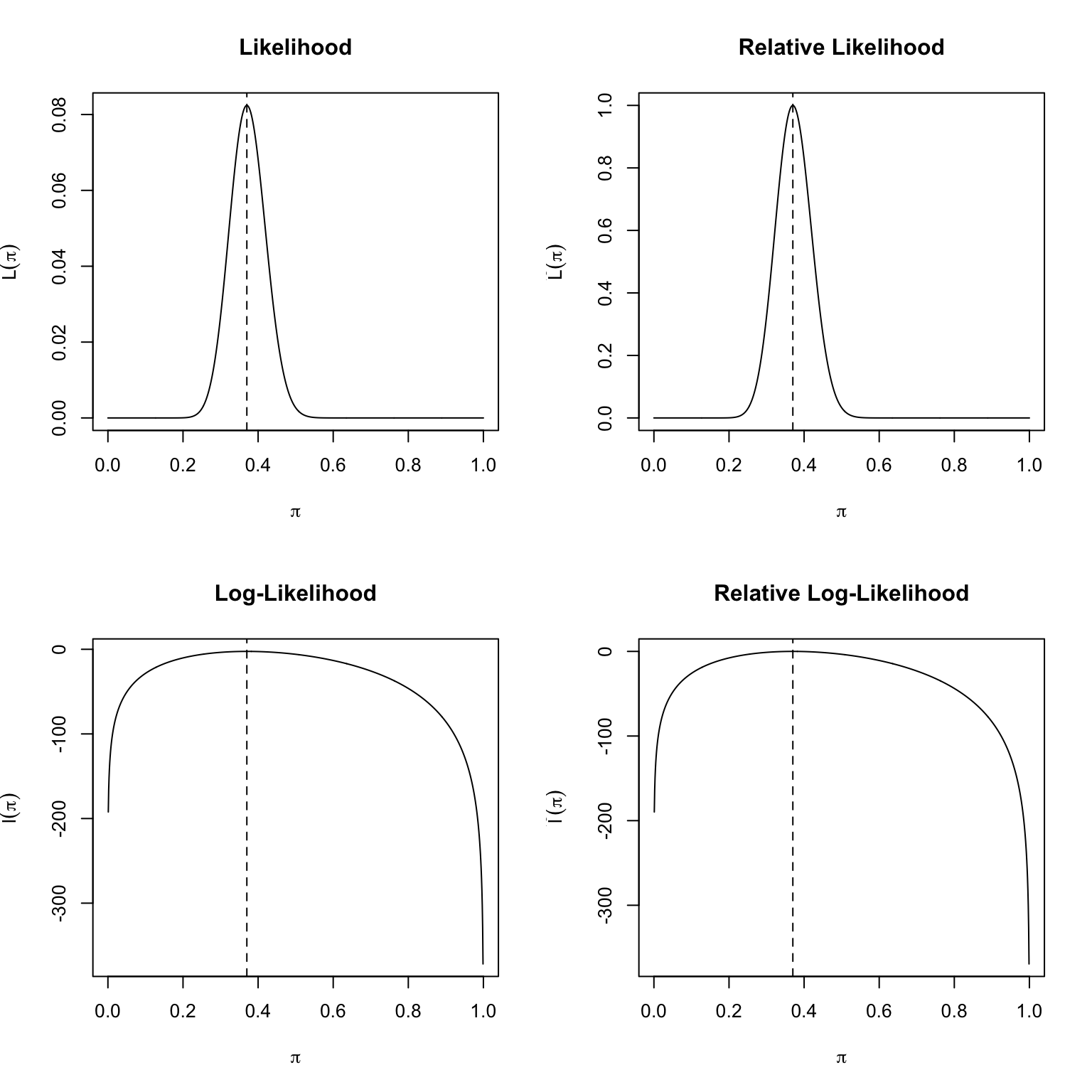
Die Likelihood-Funktion für einen Binomialparameter \(\pi\) bei vorliegenden Daten \(x=37\) und \(n=100\) kann man berechnen mit dbinom(). Dabei wird für jedes mögliche \(\pi \in [0,1]\) die Wahrscheinlichkeit \(p(x)\) berechnet und vertikal aufgetragen.
wk<-seq(0,1,.001)##Kandidaten für pi
L<-dbinom(x=37,size=100,prob=wk)##Likelihood von pi (als Funktion von pi!)
plot(wk,L,type="l",xlab=expression(pi),ylab=expression(L(pi)))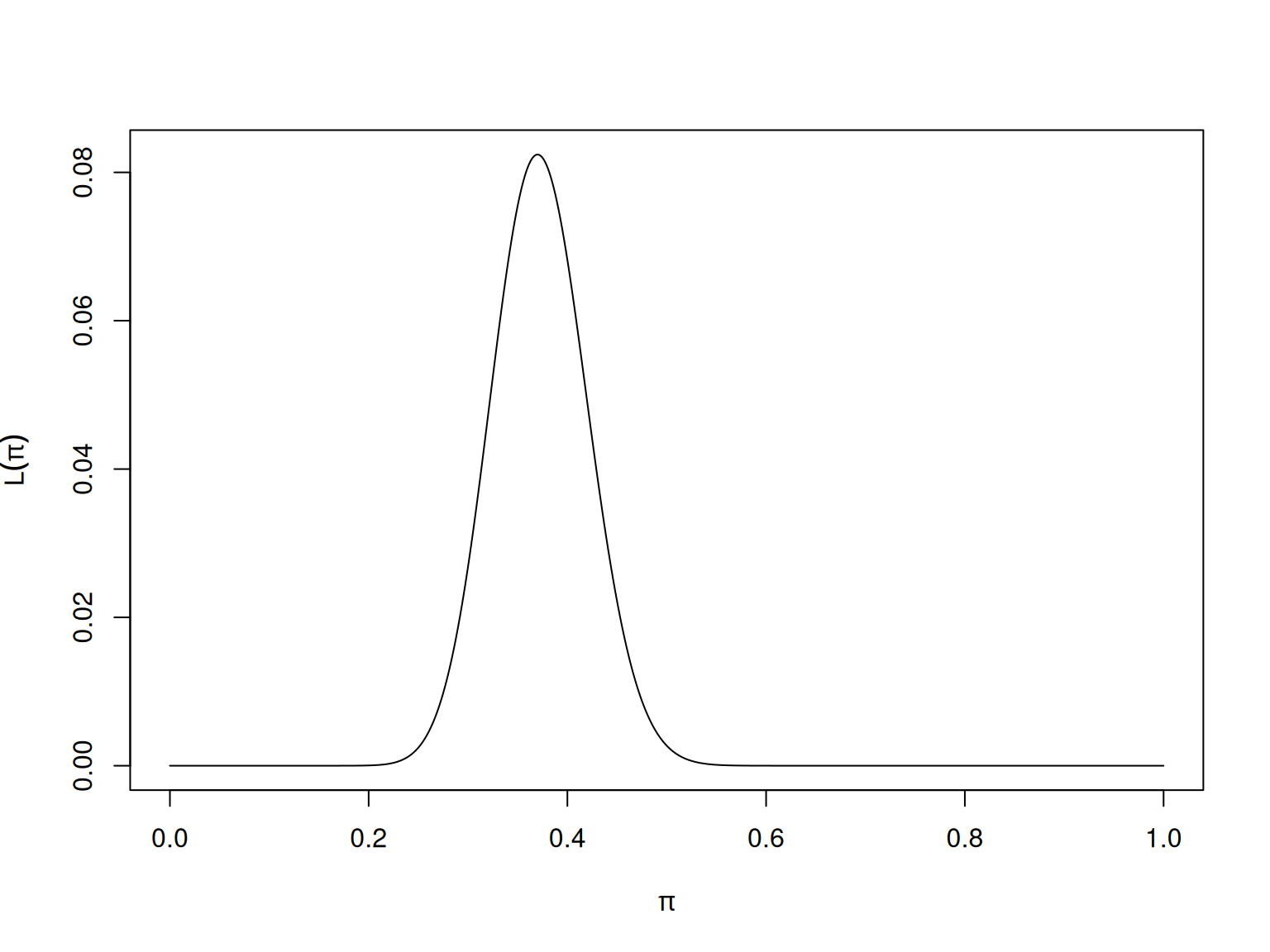
Likelihood-Funktion versus Wahrscheinlichkeitsverteilung
Die Likelihood-Funktion ist keine Wahrscheinlichkeitsverteilung, die Fläche unter \(L(\pi)\neq 1\). Sie ist eine Funktion von \(\pi\) und nicht eine Funktion von \(x\).
Die Maximum-Likelihood-Schätzung (MLE) \(\hat{\theta}_{ML}\) eines Parameters \(\theta\) wird durch Maximierung der Likelhood-Funktion erreicht:
Likelihood: Für unabhängige Daten (\(X_1,\dots,X_n\)) ist die Likelihood von \(\theta\), d.h. die Wahrscheinlichkeitsdichte (oder -masse) der Daten gegeben \(\theta\), gleich dem Produkt der \(n\) Wahrscheinlichkeitsdichten (oder -massen) \(p(x_i)\), wobei \(p(x_i)\) die Dichten (oder Massen) sind,
\[\begin{equation} L(\theta)=\prod_{i=1}^n p(x_i). \end{equation}\]
Log-Likelihood: Aus numerischen Gründen wird dann meistens die Log-Likelihood \(l(\theta)\) verwendet. Aus einem Produkt von Likelihoods wird dann eine Summe von Log-Likelihoods, was numerisch leichter zu handhaben ist,
\[\begin{equation} l(\theta)=\log L(\theta)=\sum_{i=1}^n \log p(x_i). \end{equation}\]
Relative Likelihood und relative Log-Likelihood: Es ist oft nützlich, die Likelihood- oder Log-Likelihood relativ zu ihrem Wert beim MLE zu betrachten. Die relative Likelihood ist
\[\begin{equation} \tilde{L}(\theta)=\frac{L(\theta)}{L(\hat{\theta}_{ML})} \end{equation}\]
Folgende Schwellen werden of gebraucht bezüglich Plausibilität von \(\theta\)
\[\begin{align*} 1&\geq \tilde{L}(\theta) >\frac{1}{3} &\quad \theta &\text{\,\,very\,plausible}\\ \frac{1}{3} &\geq \tilde{L}(\theta) >\frac{1}{10} &\quad \theta &\text{\,\,plausible}\\ \frac{1}{10} &\geq \tilde{L}(\theta) >\frac{1}{100} &\quad \theta &\text{\,\,less \,plausible}\\ \frac{1}{100} &\geq \tilde{L}(\theta) > \frac{1}{1000} &\quad \theta &\text{\,\,barely\,plausible}\\ \frac{1}{1000} &\geq \tilde{L}(\theta) >0 &\quad \theta &\text{\,\,not\, plausible} \end{align*}\]
Die relative Log-Likelhood ist dann
\[\begin{equation} \tilde{l}(\theta)=l(\theta)-l(\hat{\theta}_{ML}) =\log\frac{L(\theta)}{L(\hat{\theta}_{ML})}. \end{equation}\]
Dabei gilt \(-\infty <\tilde{l}(\theta)\leq 0\) und \(\tilde{l}(\hat{\theta}_{ML})=0\).
Abbildung 9.8 zeigt die verschiedenen Arten der Likelihood für unser Binomialmodell bei vorliegenden Daten \(n = 100\) und \(x = 37\). Der Maximum-Likelihood-Schätzer ist gut ablesbar als \(\hat{\pi}_{ML}=0.37\).
9.7.3.2 Score und Information
Die erste Ableitung der Log-Likelihood-Funktion wird als Score-Funktion bezeichnet,
\[\begin{equation} S(\theta)=\frac{dl(\theta)}{d\theta}. \end{equation}\]
Die Berechnung des Maximum-Likelihood-Schätzers (MLE) erfolgt typischerweise durch das Lösen der Score-Gleichung \(S(\theta) = 0\).
Die negative zweite Ableitung der Log-Likelihood-Funktion (die negative Krümmung, die misst, wie schnell eine Kurve an einem bestimmten Punkt ihre Richtung ändert), wird als Fisher-Information bezeichnet,
\[\begin{equation} I(\theta)=-\frac{d^2l(\theta)}{d\theta^2}=-\frac{dS(\theta)}{d\theta}. \end{equation}\]
9.7.3.3 Beispiel: Binomial model
Unter Binomialverteilung haben wir (für die Interessierten):
\(L(\pi)={n \choose x}\pi^x(1-\pi)^{n-x}\)
\(l(\pi)=x \log(\pi)+(n-x) \log(1-\pi)\)
\(S(\pi)=\frac{x}{\pi}-\frac{n-x}{1-\pi}\)
\(\hat{\pi}_{ML}=\frac{x}{n}\)
\(I(\pi)=\frac{x}{\pi^2}+\frac{n-x}{(1-\pi)^2}\)
9.7.3.4 Varianz des MLE als Inverse der Fisher-Information
Die Fisher Information evaluiert am MLE \(\hat{\pi}_{ML}\) ist
\[\begin{equation} I(\hat{\pi}_{ML})=\frac{n}{\hat{\pi}_{ML}(1-\hat{\pi}_{ML})} \end{equation}\]
Man kann zeigen, dass die Varianz \(\Var(\hat{\pi}_{ML})\) approximativ dem Kehrwert der Fisher-Information entspricht. Je grösser die Information, umso kleiner die Varianz und umgekehrt. Das macht auch intuitiv Sinn.
\[ \Var(\hat{\pi}_{ML})=\frac{1}{I(\hat{\pi}_{ML})} \]
Damit haben wir einen Standardfehler für den MLE
\[\begin{equation} SE(\hat{\pi}_{ML})=\sqrt{\frac{1}{I(\hat{\pi}_{ML})}}=\sqrt{\frac{\hat{\pi}_{ML}(1-\hat{\pi}_{ML})}{n}}. \end{equation}\]
9.7.3.5 Quadratische Approximation
Quadratische Approximation der Log-Likelihood
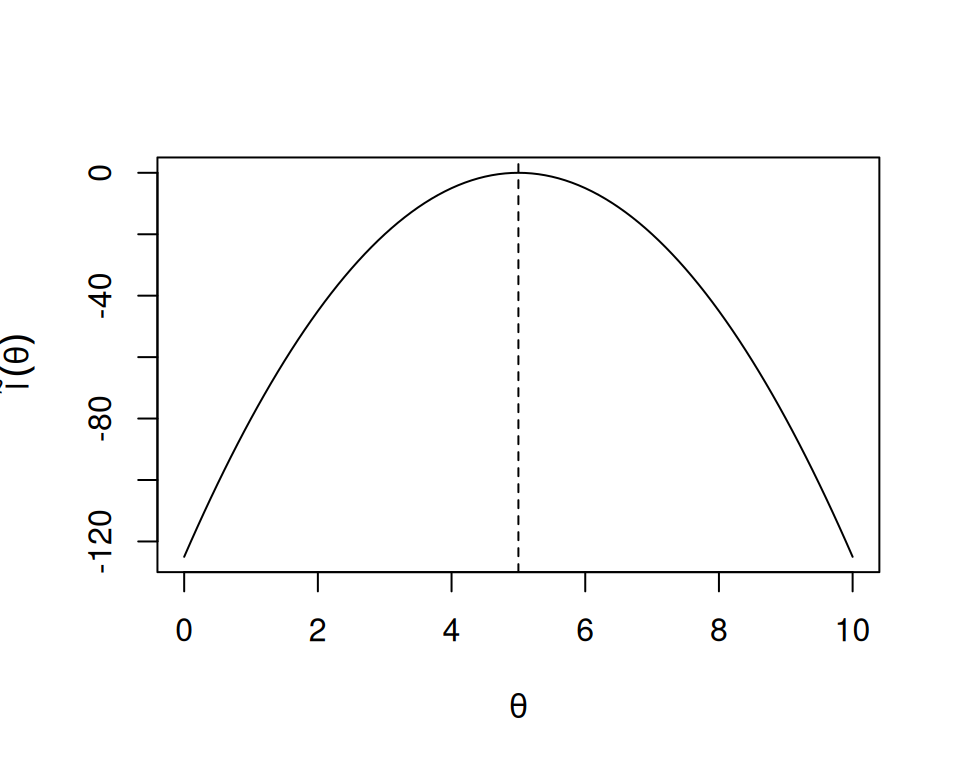
Die quadratische Approximation an die relative Log-Likelihood ist
\[\begin{equation} \large \tilde{l}(\theta)=l(\theta)-l(\hat{\theta}_{ML})\approx -\frac{1}{2}I(\hat{\theta}_{ML})(\theta-\hat{\theta}_{ML})^2 \end{equation}\]
Proof. (Für die Interessierten!) Die Taylor Approximation zweiten Grades entwickelt um MLE ist: \[\begin{align*} l(\theta)&\approx l(\hat{\theta}_{ML})+\frac{dl(\hat{\theta}_{ML})}{d\theta}(\theta-\hat{\theta}_{ML})+\frac{1}{2}\frac{d^2l(\hat{\theta}_{ML})}{d\theta^2}(\theta-\hat{\theta}_{ML})^2\\ &=l(\hat{\theta}_{ML})+S(\hat{\theta}_{ML})(\theta-\hat{\theta}_{ML})-\frac{1}{2}I(\hat{\theta}_{ML})(\theta-\hat{\theta}_{ML})^2\\ &=l(\hat{\theta}_{ML})+0-\frac{1}{2}I(\hat{\theta}_{ML})(\theta-\hat{\theta}_{ML})^2\\ &=l(\hat{\theta}_{ML})-\frac{1}{2}I(\hat{\theta}_{ML})(\theta-\hat{\theta}_{ML})^2 \end{align*}\]
Beispiel. Für \(I(\hat{\theta}_{ML})=10\) und \(\hat{\theta}_{ML}=5\), haben wir \(y=-0.5\times 10(x-5)^2\). Dies ist eine einfache quadratische Funktion von \(\theta\) zentriert um \(\hat{\theta}_{ML}=5\) mit negativer Krümmung \(I(\hat{\theta}_{ML})=10\).
Wir brauchen nun obiges Resultat, dass die Varianz vom MLE der Kehrwert der Information ist, \[\Var(\hat{\theta}_{ML})=1/I(\hat{\theta}_{ML}), \] und können die relative Log-Likelihood schreiben als
Quadratische Approximation der Log-Likelihood
\[\begin{equation} \large \tilde{l}(\theta)\approx -\frac{1}{2}\left(\frac{\hat{\theta}_{ML}-\theta}{SE(\hat{\theta}_{ML})}\right)^2 \end{equation}\]
Normalverteilung und quadratische Approximation: Bei Normalverteilung mit bekanntem \(\sigma^2\) haben wir
- \(L(\mu)=\prod_{i=1}^n\frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)\)
- \(l(\mu)=-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2\)
- \(S(\mu)=\frac{1}{\sigma^2}\sum_{i=1}^n(x_i-\mu)\)
- \(\hat{\mu}_{ML}=\bar{x}\)
- \(I(\mu)=\frac{n}{\sigma^2}\)
Wir haben dann für die relative Log-Likelihood:
\[\begin{align} \tilde{l}(\mu)&=l(\mu) - l(\hat{\mu}) \\ &= -\frac{1}{2\sigma^2} \left[ \sum_{i=1}^{n} (x_i - \mu)^2 - \sum_{i=1}^{n} (x_i - \hat{\mu})^2 \right]\\ &=-\frac{1}{2}\frac{n}{\sigma^2}(\hat{\mu}-\mu)^2\\ &=-\frac{1}{2}\left(\frac{\hat{\mu}-\mu}{\sigma/\sqrt{n}}\right)^2. \end{align}\]
Die Approximation ist also bei Normalverteilung exakt!
Wir sehen, dass die Log-Likelihood bei Normalverteilung eine quadratische Funktion ist und dass die Information (negative Krümmung) und damit die Varianz nicht von \(\mu\) abhängt (homogene Varianz).
Normalverteilung und quadratische Approximation
Die quadratische Approximation der Log-Likelihood ist bei Normalverteilung exakt! Das bedeutet:
- Normalverteilung impliziert quadratische Log-Likelihood
- Eine quadratische Approximation der Log-Likelihood impliziert approximative Normalverteilung
Die Vorteile der quadratischen Approximation der relativen Log-Likelihood liegen darin, dass wir nur den MLE und die beobachtete Fisher-Information kennen müssen, unabhängig davon, wie die tatsächliche Log-Likelihood aussieht.
9.7.4 Likelihood Inferenz
Wir betrachten nun Statistiken, mit denen wir Hypothesen testen können. Aus der Likelihood-Theorie kann man die asymptotische Verteilung von drei Statistiken ableiten, um Hypothesen der Form
\[ H_0: \theta=\theta_0 \]
zu testen und Konfidenzintervalle für \(\theta\) zu konstruieren:
Wir wollen diese drei Statistiken und deren Verteilung unter der \(H_0\) jetzt aufführen (ohne Herleitung)
- Wald-Statistik
- Score-Statistik
- Likelihood-Ratio Statistik
9.7.4.1 Wald Tests
Wald-Statistik
\[\begin{equation} \Large \frac{\hat{\theta}_{ML}-\theta_0}{SE(\hat{\theta}_{ML})}\overset{a}\sim \mathcal{N}(0,1) \end{equation}\]
Tests einzelner Koeffizienten, die auf der approximativen Normalverteilung basieren, werden als Wald-Tests bezeichnet, wobei eine grobe Annahme über die Form der Likelihood getroffen wird. Tests im Output von logistischen Regressionen sind Beispiele für Wald Tests.
Durch das Invertieren von Tests können wir Konfidenzintervalle konstruieren:
Die Menge
\[\begin{equation} \left(\theta: z_{\alpha/2}\leq \frac{\hat{\theta}_{ML}-\theta}{SE(\hat{\theta}_{ML})} \leq z_{1-\alpha/2}\right) \end{equation}\]
führt nicht zu einer Verwerfung von \(H_0: \theta=\theta_0\). Diese Werte bilden also ein approximates \((1-\alpha)\times 100\) Wald Konfidenzintervall für \(\theta\). Das ist dann äquivalent zur bereits bekannten Formel
\[\begin{equation} \boxed{\hat{\theta}_{ML}\pm z_{1-\alpha/2} SE(\hat{\theta}_{ML})}. \end{equation}\]
9.7.4.2 Likelihood Ratio Tests
Eine sehr wichtige Statistik ist die Likelihood-Ratio-Statistik, diese führt zum Likelihood-Ratio-Test. Der Likelihood-Ratio-Test ein Hypothesentest, bei dem die Güte der Anpassung zweier konkurrierender statistischer Modelle verglichen wird. Typischerweise wird dabei ein Modell betrachtet, das durch Maximierung über den gesamten Parameterraum gefunden wird, und ein weiteres, das nach der Auferlegung einer Einschränkung bestimmt wird.
Dieser Test basiert auf dem Verhältnis ihrer Likelihoods. Wenn das stärker eingeschränkte Modell (d.h. die Nullhypothese) durch die beobachteten Daten gestützt wird, sollten sich die beiden Likelihoods nicht stärker unterscheiden als es durch Stichprobenfehler erklärbar wäre.
Der Likelihood-Ratio-Test prüft also, ob dieses Verhältnis signifikant von Eins abweicht, oder äquivalent dazu, ob sein natürlicher Logarithmus signifikant von Null abweicht.
Likelihood-Ratio-Tests verwenden die Likelihood, wie sie ist. Daher sind LR-Tests in der Regel den Wald-Tests überlegen. Sie sind asymptotisch aber äquivalent.
Unter der Nullhypothese ist die Likelihood-Ratio-Statistik ist \(\chi^2\)-verteilt mit einem Freiheitsgrad (wenn nur ein Parameter geschätzt wird). Die \(\chi^2\)-Verteilung haben wir in Section 9.3 bereits kennengelernt:
Likelihood-Ratio Statistik
\[\begin{equation} \Large -2 \tilde{l}(\theta_0)=-2(l(\theta_0)-l(\hat{\theta}_{ML}))\overset{a}\sim \chi^2(1). \end{equation}\]
Beispiel Binomialverteilung: Wir testen
\[H_0: \pi=0.2\]
mit den Daten \(x=37\) und \(n=100\). Die Log-Likelihood beim MLE \(\hat{\pi}=0.37\) ist -2.4961214. Die Log-Likelihood bei \(\pi_0=0.2\) ist -10.2077998. Die Likelihood-Ratio Statistik ist dann
\[ LR=-2(l(\pi_0)-l(\hat{\pi}_{ML}))= 15.4233568 \]
und die Wahrscheinlichkeit für \(LR>15.4233568\) ist kleiner als 5%:
llMLE<-dbinom(x=37,size=100,prob=0.37,log=TRUE)
ll0<-dbinom(x=37,size=100,prob=0.20,log=TRUE)
LR<- -2*(ll0-llMLE)
p<-1-pchisq(LR,1)
round(c(llMLE=llMLE,ll0=ll0,LR=LR,p=p),4) llMLE ll0 LR p
-2.4961 -10.2078 15.4234 0.0001 Wir haben somit Evidenz gegen \(H_0\).
Die Menge
\[\begin{equation} \left(\pi:\tilde{l}(\pi)\geq -\frac{1}{2}\chi^2_{1-\alpha}(1)\right) \end{equation}\]
bildet ein approximates \((1-\alpha)\times 100\) percent Likelihood-Ratio Konfidenzintervall für \(\pi\). Für ein 95% Konfidenzintervall ist das die Menge \(\left(\pi:\tilde{l}(\pi)\geq -1.9207294 \right)\). In unserem Beispiel wäre dies
pi<-seq(0,1,by=.0001)
l<-dbinom(x=37,size=100,prob=pi,log=TRUE)
rl<-l-max(l)
range(pi[-2*rl < qchisq(0.95,1)])[1] 0.2796 0.46709.7.4.3 Score Tests
Score-Statistik
\[\begin{equation} \Large \frac{S(\theta_0)}{\sqrt{I(\theta_0)}}\overset{a}\sim \mathcal{N}(0,1) \end{equation}\]
Auf die Score-Tests und diesbezüglich Intervallschätzungen gehen wir hier nicht näher direkt ein. Für den Score-Test muss nur die Likelihood bei \(\theta=\theta_0\) berechnet werden. Der Score ist ja die Steigung der Likelhood. Je grösser die Steigung der Likelhood bei \(\theta_0\), umso extremer ist die Statistik. Beim MLE ist der Score Null. Wir haben in Section 8.4.2 prop.test() für Tests von Proportionen gesehen, das war ein Beispiel für einen Score-Test.
9.7.4.4 Zusammenfassung
Die drei klassischen Tests für die Hypothese \(H_0: \theta = \theta_0\) basieren auf unterschiedlichen Prinzipien, sind aber asymptotisch äquivalent:
- Wald-Test: basiert auf der Schätzung \(\hat{\theta}_{ML}\) und deren Standardfehler.
- Score-Test: verwendet die Ableitung der Log-Likelihood an der Nullhypothese.
- Likelihood-Ratio-Test: vergleicht die Likelihood unter \(H_0\) und unter der Maximum-Likelihood-Schätzung.
| Test | Teststatistik |
|---|---|
| Wald-Test | \(W = \dfrac{\hat{\theta}_{ML} - \theta_0}{SE(\hat{\theta}_{ML})} \overset{a}{\sim} \mathcal{N}(0,1)\) |
| Score-Test | \(Z_S = \dfrac{S(\theta_0)}{\sqrt{I(\theta_0)}} \overset{a}{\sim} \mathcal{N}(0,1)\) |
| Likelihood-Ratio-Test | \(LR = -2 \log \left( \dfrac{L(\theta_0)}{L(\hat{\theta}_{ML})} \right) \overset{a}{\sim} \chi^2(1)\) |
Notation:
- \(\hat{\theta}_{ML}\): Maximum-Likelihood-Schätzer
- \(SE(\hat{\theta}_{ML})\): Standardfehler des Schätzers
- \(S(\theta_0)\): Score-Funktion (erste Ableitung der Log-Likelihood an \(\theta_0\))
- \(I(\theta_0)\): Fisher-Information an \(\theta_0\)
- \(L(\theta)\): Likelihood-Funktion
Note
Alle drei Tests sind für grosse Stichproben asymptotisch äquivalent. Für kleine Stichproben können die Ergebnisse abweichen.
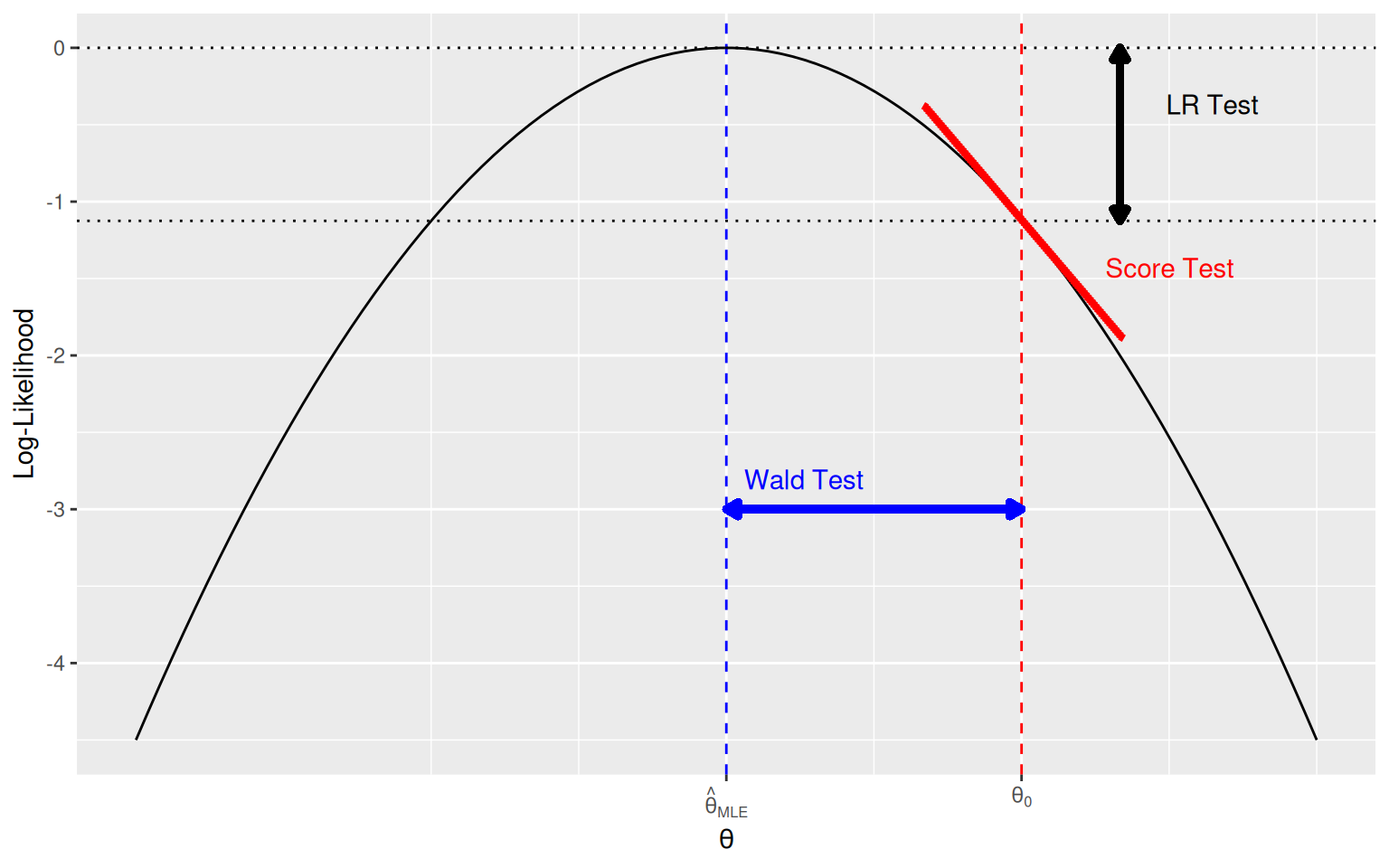
Abbildung 9.9 illustriert die auf der Likelihood-Theorie basierenden asymptotischen Tests für ein Ein-Parameter-Modell mit zu schätzendem Parameter \(\theta\) und dem reduzierten Modell mit fixiertem \(\theta=\theta_0\).
- Für den Wald-Test muss nur das nicht reduzierte Modell geschätzt werden.
- Für den Score-Test muss nur das reduzierte Modell geschätzt werden.
- Für den LR-Test müssen das nicht reduzierte und das reduzierte (\(H_0\))-Model berechnet werden.
Eine Shiny-App dazu kann man in R laufen lassen mit
shiny::runGitHub("Trinity","mcdr65")oder direkt betrachten über Asymptotic Tests.
9.7.4.5 Vergleich von Wald und LR-Konfidenzintervallen
Abbildung 9.10 zeigt die relative Log-Likelihood für \(\pi\) für unsere Beobachtung \(x=37\) auf \(n=100\). Die gestrichelte Linie ist die quadratische Approximation, die blaue Linie ist das Wald Konfidenzintervall und die schwarze das Likelihood Ratio Konfidenzintervall. Wald-Intervalle sind oft ungeeignet, vor allem an der Grenze vom Parameterraum oder bei kleinen Stichproben.
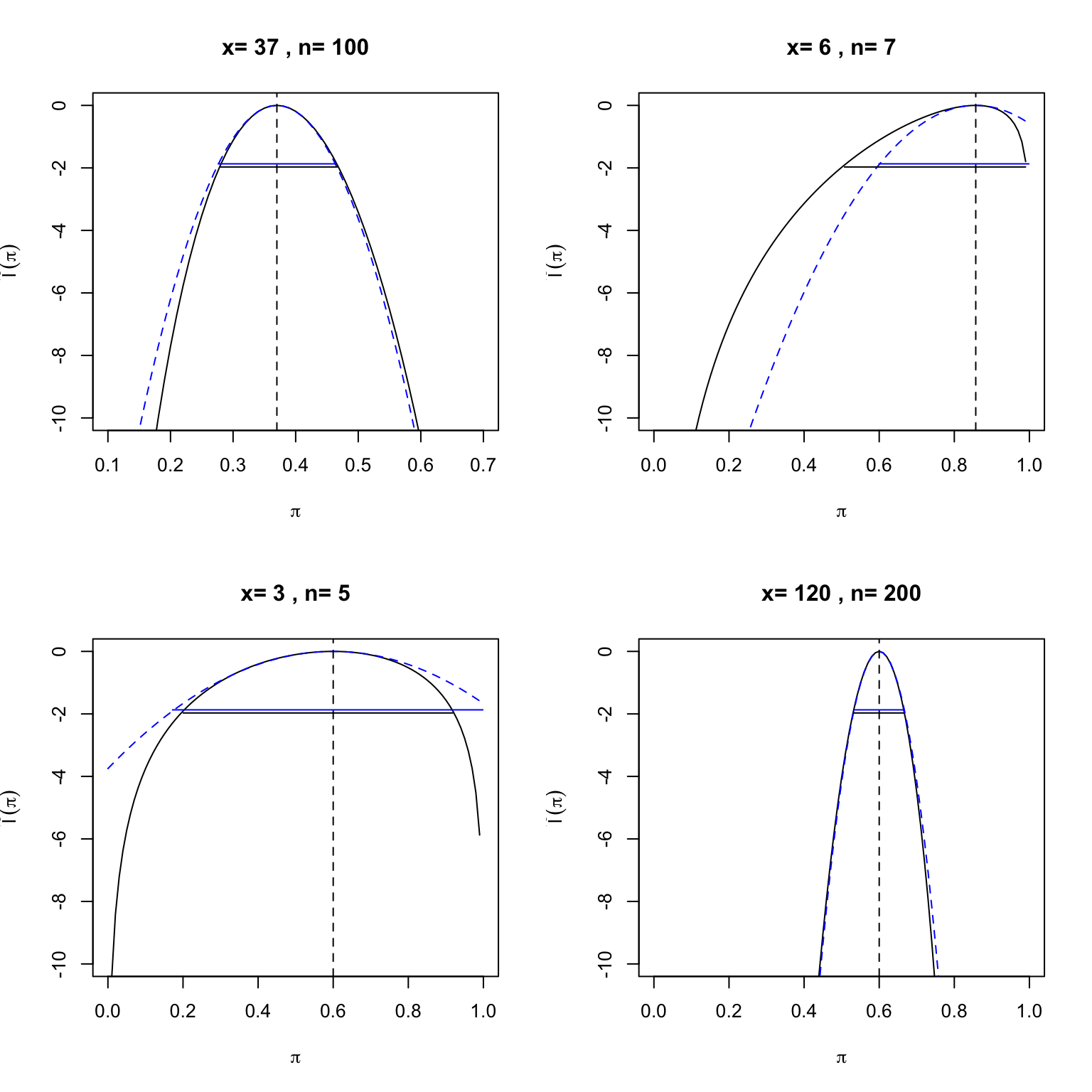
Die Funktion confint() konstruiert Likelihood-Konfidenzintervalle, wenn ein GLM-Objekt als Argument übergeben wird.
9.7.5 Zusammenfassung Likelihood
Die wichtigsten Punkte hier noch einmal zusammengefasst:
- Die Likelihood eines Parameterwertes \(L(\theta)\) ist die Wahrscheinlichkeits(dichte) der beobachteten Daten \(x\), gesehen als eine Funktion des unbekannten Parameters \(\theta\),
\[ L(\theta)=p(x;\theta). \]
Aus mathematischen und numerischen Gründen ist man oft nicht an \(L\) interessiert, sondern an der Log-Likelihood.
Der Likelihood Approach ist eine generelle Methode, um Parameter zu schätzen und Hypothesen zu testen. Der beste Schätzwert für den Parameter ist jener, welcher die Likelihood-Funktion maximiert (Maximum Likelihood estimate \(MLE\)).
Parameter in Regressionsmodellen wie der logistischen oder der Poisson Regression werden auf diese Art geschätzt.
Die Likelihood-Theorie führt zur Wald-, LR-, und Score-Statistik. Mit diesen Statistiken können Tests bezüglich den Parametern gemacht und Konfidenzintervalle konstruiert werden.
Der Vorteil des Likelihood Approaches ist, dass er auf komplexe Modelle mit vielen Parametern generalisiert werden kann.
Wenn der Stichprobenumfang gross genug ist, kann die Likelihood durch eine quadratische Funktion approximiert werden. Mittels dieser quadratischen Approximation können Standardfehler, Konfidenzintervalle und P-Werte einfacher berechnet werden. Bei Normalverteilung ist diese Approximation sogar exakt. Hypothesentests auf Grundlage der quadratischen Approximation nennt man Wald Tests.
P-Werte in den Outputs von logistischen oder einer Poisson Regressionen sind Beispiele für Wald Tests.
9.8 Verschachtelte Modelle
Wie bereits bei der multiplen linearen Regression gehen wir auch hier nicht im Detail darauf ein, wie man die Prädiktorvariablen für eine multiple logistische Regression auswählt. In den Übungen und ggf. in der Prüfung können wir jeweils der Aufgabenstellung entnehmen, welche Variablen in das Modell eingeschlossen werden sollen. Zu Illustrationszwecken wird hier der gleiche, stark vereinfachte Ansatz wie in Section 7.6 verfolgt:
Zuerst wird eine komplexes Modell mit allen Prädiktoren erstellt, unter Berücksichtigung, dass \(n \ge 10p\), wobei \(p\) = Anzahl geschätzter Regressionsparameter (Harrell , 2015).
Schrittweise wird jeweils der Prädiktor mit dem höchsten P-Wert entfernt.
Das reduzierte Modell wird mit dem komplexen Modell verglichen.
Falls sich das reduzierte Modell nicht vom komplexen Modell unterscheidet, fährt man bei 2. fort.
Wir schauen uns als erstes das komplexe Modell mit allen acht Prädiktorvariablen an, welches wir weiter oben (Section 9.6) bereits erstellt haben:
summary(m.glmF)
Call:
glm(formula = diabetes ~ pregnant_bin + glucose + pressure +
triceps + insulin + mass + pedigree + age, family = binomial(),
data = diabetes)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.017e+01 1.307e+00 -7.776 7.47e-15 ***
pregnant_binYes 2.107e-03 4.223e-01 0.005 0.996019
glucose 3.820e-02 5.785e-03 6.603 4.04e-11 ***
pressure -1.079e-03 1.180e-02 -0.091 0.927170
triceps 1.168e-02 1.717e-02 0.680 0.496209
insulin -9.425e-04 1.327e-03 -0.710 0.477665
mass 6.662e-02 2.766e-02 2.409 0.015993 *
pedigree 1.079e+00 4.228e-01 2.551 0.010727 *
age 5.201e-02 1.483e-02 3.506 0.000455 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 498.10 on 391 degrees of freedom
Residual deviance: 346.24 on 383 degrees of freedom
AIC: 364.24
Number of Fisher Scoring iterations: 5Zum Begriff der Devianz im Output kommen wir weiter unten. Obwohl die Stichprobe (\(n\) = 392) gross genug wäre um neun Regressionsparameter zu schätzen (\(\beta_0\) plus die Effekte \(\beta_1,\dots,\beta_8\)), scheinen einige Variablen nicht im Zusammenhang mit Diabetes zu stehen. Es ist darum sinnvoll, das Modell zu vereinfachen. Wir entfernen als erstes die Variable pregnant_bin. Das geht einfach mit der update() Funktion.
m.glmF2<-update(m.glmF,.~.-pregnant_bin)Anschliessend wird das reduzierte Modell mit dem ersten Modell verglichen. Dies kann mit einem Likelihood ratio Test gemacht werden:
- \(H_0\): Reduziertes Modell with \(p_{reduz}\) Parametern ist wahr.
- \(H_1\): Nicht-reduziertes Modell mit \(p_{gross}\) Parametern ist wahr.
“Das reduzierte Modell ist wahr” bedeutet ja: \(\beta_{pregnant.bin}=0\). Hier wird zuerst im grossen Modell ein Parameter fixiert, \(\beta_{pregnant_bin}=0\), darum hat die LRT-Statistik einen Freiheitsgrad.
In Multiparameter-Modellen gilt dann für den verallgemeinerten Likelihood-Ratio Test, dass die Anzahl Freiheitsgrade sich immer ergibt als der Differenz der zu schätzenden Parameter im nicht-reduzierten relativ zum reduzierten Modell.
Die verallgemeinerte Likelihood-Ratio Statistik ist dann
Verallgemeinerte Likelihood-Ratio Statistik
\[ \Large -2(l_{reduz}-l_{gross}) \overset{a}\sim \chi^2_{p_{gross}-p_{reduz}} \]
Die Grösse \(-2(l_{reduz}-l_{gross})\) ist der Unterschied in der Devianz zwischen dem reduzierten und dem nicht reduzierten Modell.
Die Devianz eines Modells ist \(-2(l_{reduz}-l_{saturated})\) mit \(l_{saturated}\) als der Log-likelihood des maximalen Modells (ein Modell mit einem Parameter für jede Beobachtung \(i\), also der bestmögliche Fit)
\[ \begin{align} D_{small}-D_{large}&=-2(l_{small}-l_{saturated})-(-2(l_{large}-l_{saturated}))\\ &=-2(l_{small}-l_{large}) \end{align} \]
Hier wird die Funktion lrtest() aus dem lmtest Package dazu verwendet (anova() wäre hier äquivalent). Wir schreiben anova(kleines Modell, grosses Modell):
library(lmtest)
lrtest (m.glmF2, m.glmF)Likelihood ratio test
Model 1: diabetes ~ glucose + pressure + triceps + insulin + mass + pedigree +
age
Model 2: diabetes ~ pregnant_bin + glucose + pressure + triceps + insulin +
mass + pedigree + age
#Df LogLik Df Chisq Pr(>Chisq)
1 8 -173.12
2 9 -173.12 1 0 0.996# anova(m.glmF2, m.glmF,test="Chisq") # äquivalentWir haben keine Evidenz gegen das Nullmodell (das reduzierte Modell). Aus statistischer Sicht kann man also gut auf die Variable pregnant_bin verzichten. Im nächsten Schritt wird zusätzlich die Variable pressure entfernt. Anschliessend erfolgt wiederum der Vergleich mit dem ersten Modell.
Likelihood ratio test
Model 1: diabetes ~ glucose + triceps + insulin + mass + pedigree + age
Model 2: diabetes ~ pregnant_bin + glucose + pressure + triceps + insulin +
mass + pedigree + age
#Df LogLik Df Chisq Pr(>Chisq)
1 7 -173.12
2 9 -173.12 2 0.0086 0.9957Dem Output entnehmen wird, dass das Modell ohne die Variablen pregnant_bin und pressure (im Output Model 1) nicht verworfen werden kann.
Wenn man dieses Prozedere nun weiterführt, dann kann man nebst den Variablen pregnant_bin und pressure auch auf die Variablen triceps, insulin und pedigree verzichten (d.h. ohne dass man das jeweils reduzierte Modell verwerfen kann).
Likelihood ratio test
Model 1: diabetes ~ glucose + insulin + mass + pedigree + age
Model 2: diabetes ~ pregnant_bin + glucose + pressure + triceps + insulin +
mass + pedigree + age
#Df LogLik Df Chisq Pr(>Chisq)
1 6 -173.35
2 9 -173.12 3 0.4711 0.9252Likelihood ratio test
Model 1: diabetes ~ glucose + mass + pedigree + age
Model 2: diabetes ~ pregnant_bin + glucose + pressure + triceps + insulin +
mass + pedigree + age
#Df LogLik Df Chisq Pr(>Chisq)
1 5 -173.62
2 9 -173.12 4 0.9995 0.9099Likelihood ratio test
Model 1: diabetes ~ glucose + mass + age
Model 2: diabetes ~ pregnant_bin + glucose + pressure + triceps + insulin +
mass + pedigree + age
#Df LogLik Df Chisq Pr(>Chisq)
1 4 -177.18
2 9 -173.12 5 8.1301 0.1492Erst durch die Wegnahme von mass ist das neue reduzierte Modell zu verwerfen:
Likelihood ratio test
Model 1: diabetes ~ glucose + age
Model 2: diabetes ~ pregnant_bin + glucose + pressure + triceps + insulin +
mass + pedigree + age
#Df LogLik Df Chisq Pr(>Chisq)
1 3 -185.34
2 9 -173.12 6 24.454 0.0004307 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Modellvergleich
Letzteren Modellvergleich können wir reproduzieren mit:
(dl<-deviance(m.glmF))[1] 346.2355(ds<-deviance(m.glmF7))[1] 370.6897(LR<-ds-dl)[1] 24.454211-pchisq(LR,6)[1] 0.0004307352Somit beinhaltet das finale Modell die Prädiktoren glucose, mass und age:
Call:
glm(formula = diabetes ~ glucose + mass + age, family = binomial(),
data = diabetes)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -9.677346 1.041873 -9.288 < 2e-16 ***
glucose 0.036266 0.004906 7.391 1.45e-13 ***
mass 0.077860 0.020120 3.870 0.000109 ***
age 0.054075 0.013236 4.085 4.40e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 498.10 on 391 degrees of freedom
Residual deviance: 354.37 on 388 degrees of freedom
AIC: 362.37
Number of Fisher Scoring iterations: 5Wir berechnen anhand dieses Modells noch einmal die Wahrscheinlichkeit, dass die vierte Person im Datensatz Diabetes hat. Die Werte für diese Person sind:
diabetes[4,c("glucose","mass","age")] glucose mass age
9 197 30.5 53Der lineare Prädiktor ist dann
\[ \begin{align} \logit(\hat{\pi}) =-9.6773458 + 0.0362656\times 197+0.07786 \times 30.5+0.0540755 \times 53 \\ =2.7077043 \end{align} \]
Die geschätzten Odds für Diabetes sind dann
\[ \hat{O} = \exp(2.70776) = 14.9956, \]
und die geschätzte Wahrscheinlichkeit
\[ \hat{\pi} = \frac{14.99566}{1+14.99566} = 0.937 \]
Modellvergleiche mit Wald-Test. Tests einzelner Koeffizienten, die im summary(m.glmF) ersichtlich sind, sind bekanntlich Wald Tests. Wir können diese auch reproduzieren als explizite Modellvergleiche mit der Wald-Statistik:
m.glmW<-update(m.glmF,.~.-insulin)## Modell ohne Insulin
summary(m.glmF)$coef[6,4]## p-Wert von Insulin[1] 0.4776647##Wald-Test als Modellvergleich
lmtest::waldtest(m.glmF,"insulin",test="Chisq")$Pr##Wald Test, gleicher p-Wert wie der Z-Test (da Z^2=Chisq(1))[1] NA 0.47766479.9 Anhang: Hilfreiche R Codes für die logistische Regression
# simulation of data
n <- 200
x1 <- rnorm(n, 50, 10)
x2 <- factor(sample(c("A", "B"), n, TRUE))
p <- plogis(-5 + 0.08 * x1 + 1.5 * (x2 == "B"))
y <- rbinom(n, 1, p)
data <- data.frame(y, x1, x2)
head(data)
# fit logistic regression
model <- glm(y ~ x1 + x2, data, family = binomial)
# summary output
summary(model) ## compare with true values
# nicer output
parameters::parameters(model,exponentiate=TRUE,digits=3)
# predictions (probability)
predict(model, newdata=data.frame(x1 = 50, x2 = "A"), type="response")
# compare two nested models
model.red <- glm(y ~ x1, data, family = binomial)
library(lmtest)
lrtest (model.red, model)