16 Effekte in Interventionsstudien
Inhalte
- Was ist ein Effekt?
- Within- und between-group Effekte
- Haupteffekte und Interaktionseffekte
- Effektgrössen
Die Risk-of-Bias Analyse von Interventionsstudien wurde im Modul Wissenschaftliches Arbeiten II auführlich behandelt und wird darum in diesem Kaptil nicht mehr aufgegriffen.
16.1 Was ist ein Effekt?
Die korrekte Interpretation von Effekten ist unter Berücksichtigung einer soliden Risk-of-Bias Analyse bei Interventionsstudien zentral. In diesem Kapitel wird der Begriff Effekt so aufgegriffen und vertieft, dass Sie im Kontext unterschiedlicher Designs, etwa bei mehr als zwei Gruppen oder mehreren Messzeitpunkten, Effekte korrekt interpretieren können. Aber was ist ein Effekt? In der Statistik verstehen wir unter einem Effekt die Differenz einer Kennzahl zwischen zwei oder mehr Gruppen oder Messzeitpunkten. Die Nullhypothese \(H_0\) geht häufig davon aus, dass kein Effekt vorhanden ist. Ein Effekt ist demnach die Differenz zwischen dem Wert der Nullhypothese und dem geschätzten Populationsparameter, z.B. einer geschätzten Mittelwertsdifferenz zwischen zwei Gruppen. In anderen Worten, unter \(H_0\) ist der Effekt = 0 (bzw. 1 bei Verhältnissen wie Odds Ratio oder Risk Ratio).
Effekte können innerhalb (within) einer Gruppe oder zwischen (between) Gruppen gemessen werden. Da der wahre Populationsparameter unbekannt ist, werden Stichproben gezogen und statistische Tests eingesetzt, um zu entscheiden, ob eine Intervention einen (statistisch signifikanten) Effekt hat. Mit einem statistischen Test lässt sich statistisch absichern, ob ein Effekt vorhanden ist, nicht aber wie stark der untersuchte Effekt ist. Der p-Wert eines statistischen Tests sagt nichts über die Grösse oder die Richtung eines Effekts aus! Um die Stärke eines Zusammenhangs oder Grösse eines Unterschiedes zu bestimmen, gibt es Masszahlen, die die Effektstärke (auch Effektgrösse, effect size) wiedergeben.
Lernziele
Die Studierenden …
- können den Begriff der internen Validität im Kontext von Interventionsstudien definieren
- können häufige Verzerrungsquellen in Interventionsstudien beschreiben und können Methoden erläutern, um diesen vorzubeugen.
- können wichtigsten Bias-Arten interpretieren, wie sie im Gate Frame beschrieben werden, und begründen die Einschätzung des Verzerrungsrisikos.
- können zwischen rohen Mittelwertdifferenzen und standardisierten Mittelwertdifferenzen unterscheiden und interpretieren diese korrekt.
- können die Effektstärke (Cohen’s d) für Gruppendifferenzen berechnen und beurteilen deren Bedeutung.
- können die Konzepte von Zeit-, Gruppen- und Interaktionseffekten in Interventionsstudien mit zwei oder mehr Gruppen erklären.
- können zwischen statistischer Signifikanz und klinischer Relevanz differenzieren und stellen deren Bedeutung im Studienkontext dar.
Wir verwenden für dieses Kapitel die Studie mit dem Titel The effect of group mindfulness - based stress reduction program and conscious yoga on the fatigue severity and global and specific life quality in women with breast cancer (Rahmani and Talepasand 2015). Obwohl verschiedene Outcomes gemessen wurden, konzentrieren wir uns hier einfachheitshalber auf die Fatigue. Höhere Werte weisen auf eine stärkere Fatigue hin.
Die Studie besteht aus zwei Gruppen, einer Kontrollgruppe und einer Interventionsgruppe. Für jede Gruppe gibt es drei Messzeitpunkte: Pre-test, Post-test und Follow-up. Die Werte, welche wir hier verwenden, habe ich anhand der deskriptiven Angaben aus der Studie simuliert (da Rohdaten nicht verfügbar). Die Resultate stimmen daher nicht exakt mit jenen im Artikel überein.
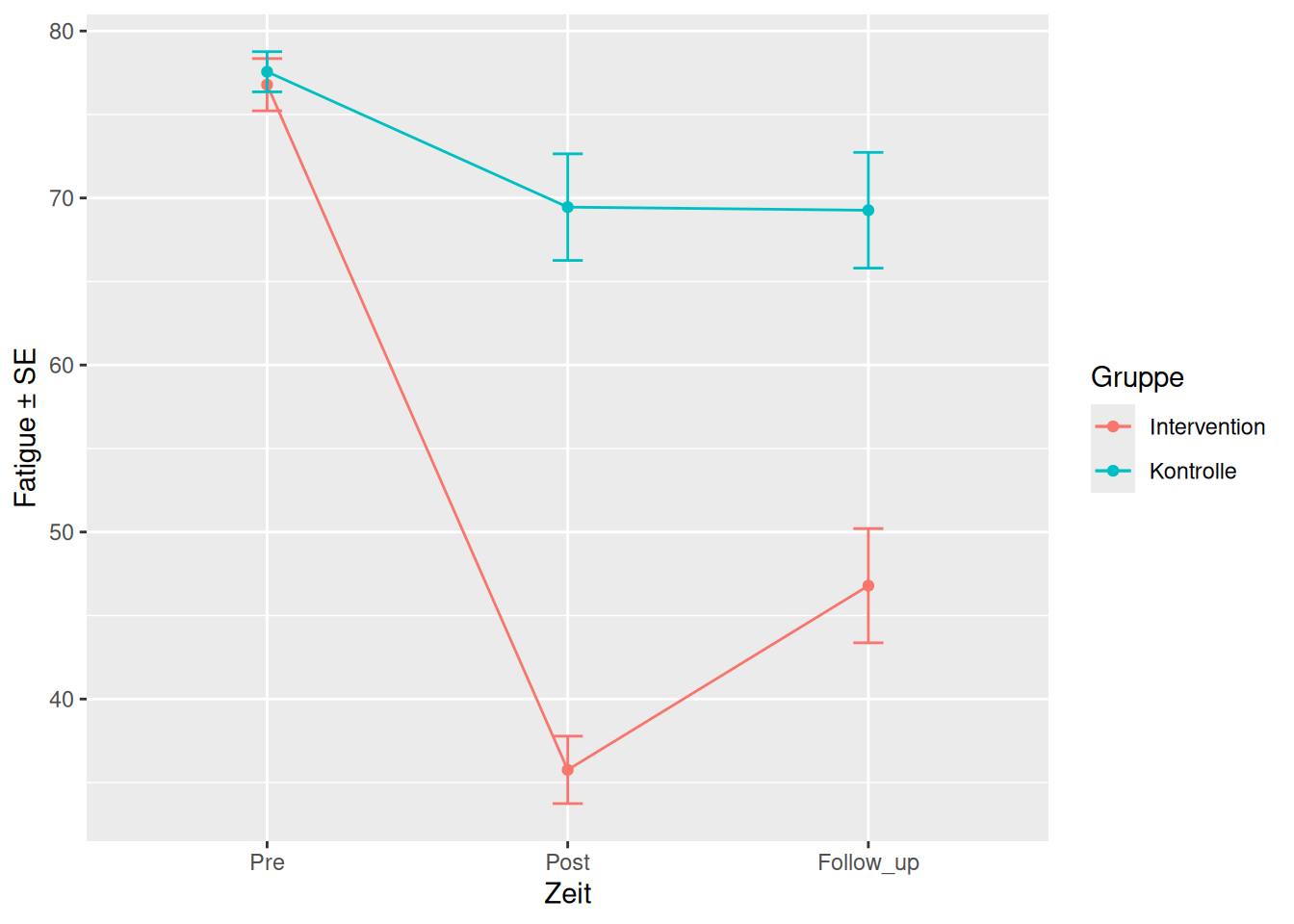
Die Daten lassen sich mit einem Interaktionsplot darstellen (Abbildung 16.1).
Im Interaktionsplot sehen wir die Mittelwerte \(\pm\) Standardfehler (also keine 95% Konfidenzintervalle!). Die deskriptiven Werte sehen Sie in Tabelle 16.1.
| Gruppe | Zeit | Mean | SD | n |
|---|---|---|---|---|
| Intervention | Pre | 76.78 | 5.42 | 12 |
| Intervention | Post | 35.76 | 6.99 | 12 |
| Intervention | Follow_up | 46.79 | 11.85 | 12 |
| Kontrolle | Pre | 77.56 | 4.17 | 12 |
| Kontrolle | Post | 69.45 | 11.05 | 12 |
| Kontrolle | Follow_up | 69.27 | 12.00 | 12 |
16.2 Within-Effekte
Je nach Fragestellung ist man an unterschiedlichen Effekten interessiert. Bei Prä-Post Vergleichen interessiert man sich für den Effekt innerhalb (within) einer Gruppe zwischen zwei Zeitpunkten. Schauen wir uns den Prä-Post Effekt in der Interventionsgruppe an:
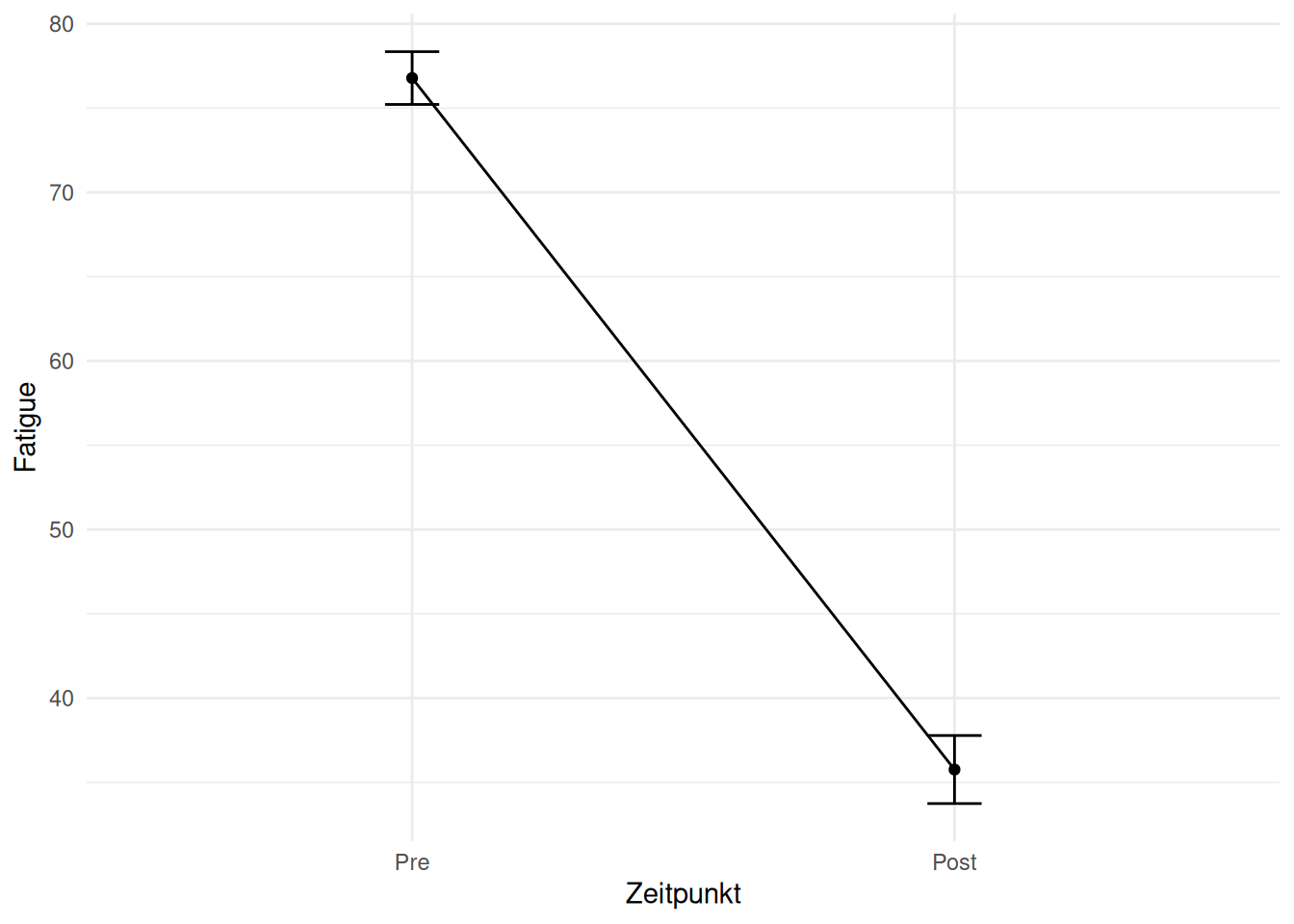
Gibt es einen Within-Effekt (Prä-Post) bei der Interventionsgruppe?
- \(H_0\): \(\mu_{pre} - \mu_{post} = 0\)
Das statistische Modell lautet: Fatigue ~ Zeit, wobei Zeit zwei Ausprägungen hat (Prä und Post). Das Modell sagt uns, dass Fatigue durch die Zeit erklärt wird. Fatigue ist die abhängige Variable, Zeit die unabhängige Variable. Ich verzichte hier bewusst auf die korrekte mathematische Formulierung, weil sie wegen den gepaarten Daten etwas komplizierter ist. Wie Sie wissen, können wir \(H_0\) mithilfe eines gepaarten \(t\)-Tests testen:
Paired t-test
data: df_ip$Pre and df_ip$Post
t = 16.764, df = 11, p-value = 3.518e-09
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
35.63959 46.41266
sample estimates:
mean difference
41.02613 Sie sehen, dass die mittlere Differenz statistisch signifikant unterschiedlich von 0 ist mit einem 95% Konfidenzintervall, welches 0 (\(H_0\)) deutlich nicht einschliesst. Die Punktschätzung von 41.03 lässt sich einfach aus den deskriptiven Werten reproduzieren (Tabelle 16.1, überprüfen Sie!). Man könnte auch eine lineare Regression verwenden, welche zum gleichen Resultat führen würde (\(t\)-Tests sind lineare Modelle).
Aus inhaltlicher Perspektive hilft uns diese Analyse nur bedingt weiter. Ohne die Kontrollgruppe mitzuberücksichtigen, können wir keine kausale Aussage zur Effektivität der Intervention machen.
16.3 Between-Effekte
Bei between-Effekten schauen wir uns die Differenz zwischen den Gruppen an. In Abbildung 16.3 sehen Sie die Werte der beiden Gruppen zum Follow-up.
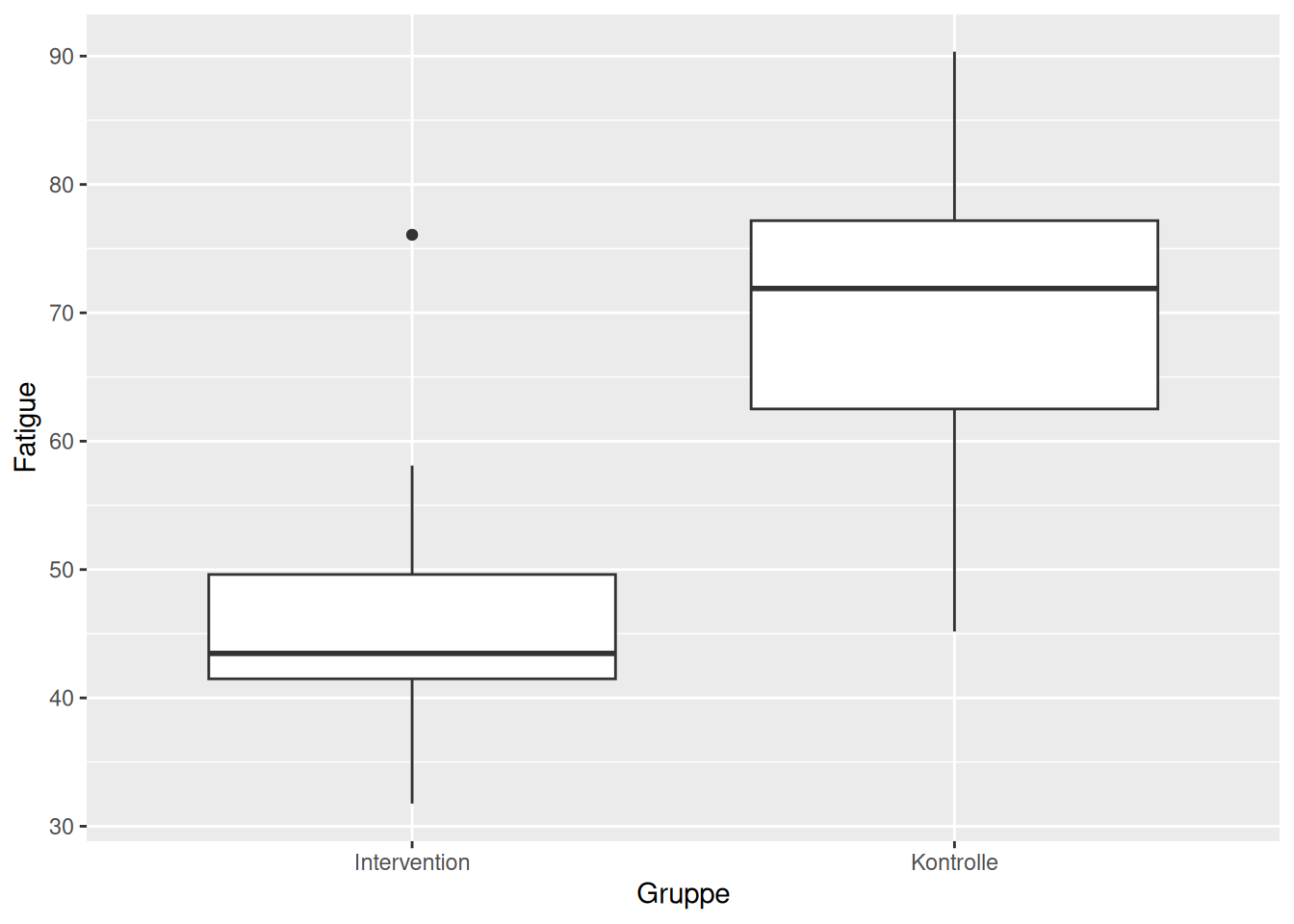
Gibt es einen between-Effekt beim Follow-up?
- \(H_0\): \(\mu_{int} - \mu_{con} = 0\)
Das statistische Modell lautet: Fatigue ~ Gruppe, wobei Gruppe zwei Ausprägungen hat. Das Modell sagt uns, dass Fatigue durch die Gruppe erklärt wird. Wir können \(H_0\) mithilfe eines zweistichproben-\(t\)-Tests testen:
Two Sample t-test
data: Fatigue by Gruppe
t = -4.6171, df = 22, p-value = 0.0001336
alternative hypothesis: true difference in means between group Intervention and group Kontrolle is not equal to 0
95 percent confidence interval:
-32.57628 -12.38226
sample estimates:
mean in group Intervention mean in group Kontrolle
46.78653 69.26579 Sie sehen, dass die Mittelwertsdifferenz signifikant verschieden von 0 ist, mit einem 95% Konfidenzintervall, welches 0 (\(H_0\)) deutlich nicht einschliesst. Die Punktschätzung von \(69.27 - 46.79 = 22.48\) lässt sich einfach aus den deskriptiven Werten reproduzieren (Tabelle 16.1). Man könnte auch eine lineare Regression verwenden, welche zum gleichen Resultat führt:
Call:
lm(formula = Fatigue ~ Gruppe, data = df.btw)
Residuals:
Min 1Q Median 3Q Max
-24.094 -6.484 -1.530 7.913 29.291
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 46.787 3.443 13.590 3.52e-12 ***
GruppeKontrolle 22.479 4.869 4.617 0.000134 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 11.93 on 22 degrees of freedom
Multiple R-squared: 0.4921, Adjusted R-squared: 0.469
F-statistic: 21.32 on 1 and 22 DF, p-value: 0.0001336\(\hat{\beta_0}\) entspricht genau dem Mittelwert der Kontrollgruppe und \(\hat{\beta_1}\) der geschätzten Mittelwertsdifferenz. Die Teststatistik \(t\) sowie der P-Wert sind identisch mit dem \(t\)-Test.
Aus inhaltlicher Perspektive hilft uns diese Analyse nur bedingt weiter. Ein alleiniger Vergleich der Werte zum Follow-up ist nur zulässig, wenn wir wissen, dass die Gruppen zu Beginn der Studie genau gleich waren (bzgl. aller relevanten Merkmale!). Das ist nur bei grossen randomisierten Studien der Fall. In dieser Situation hier (\(n\) = 12 pro Gruppe) ist es besser, wenn wir die mittlere Veränderung der beiden Gruppen vergleichen:
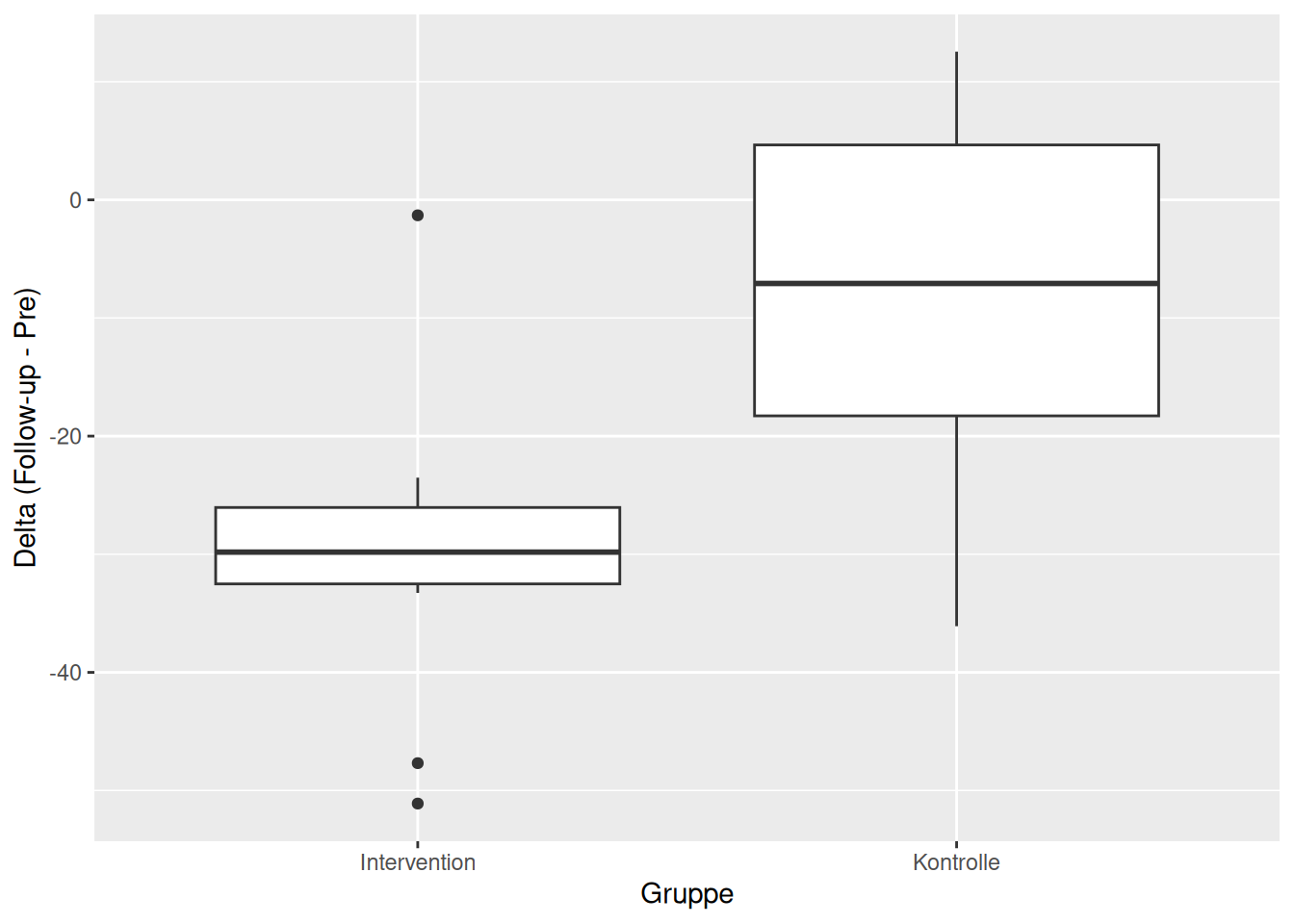
Bei nur zwei Messzeitpunkten ist dieses Vorgehen im Rahmen von RCTs effizient und korrekt. Auch hier können wir einen zweistichproben-\(t\)-Test verwenden. Das Modell lauter hier: Fatigue_Delta ~ Gruppe.
Two Sample t-test
data: Delta by Gruppe
t = -3.9332, df = 22, p-value = 0.0007097
alternative hypothesis: true difference in means between group Intervention and group Kontrolle is not equal to 0
95 percent confidence interval:
-33.14931 -10.26053
sample estimates:
mean in group Intervention mean in group Kontrolle
-29.998457 -8.293541 Auch wenn wir die Ausgangswerte berücksichtigen, finden wir einen statistisch signifikanten Effekt: Die Veränderung der Fatigue ist in der Interventionsgruppe statistisch signifikant anders (extremer), als in der Kontrollgruppe.
Die Einschränkung dabei ist, dass man nur zwei Zeitpunkte berücksichtigen kann. Es könnte sein, dass die Gruppe bei Pre-Test und Follow-up gleich sind, jedoch ein Unterschied zum Zeitpunkt Post-Test besteht. Dieser Unterschied, welcher je nach Kontext relevant sein kann, wird mit dem oben ausgeführten Verfahren nicht entdeckt. Das gleiche gilt für den Fall mit > 2 Gruppen. Wir können dann nicht mehr einen \(t\)-Test durchführen. Die Idee, für alle paarweisen Vergleiche jeweils einen \(t\)-Test durchzuführen ist schlecht: Mit jedem durchgeführten Test kumuliert sich die Wahrscheinlichkeit für einen Fehler 1. Art (\(\alpha\)).
16.4 Haupteffekte
Wenn die Gruppen-variable oder die Zeit-Variable (oder beide) mehr als zwei Ausprägungen haben, brauchen wir statistische Verfahren, welche diesen Ansprüchen gerecht werden. Das führt uns zur mulitplen linearen Regression (auch ANOVA). Wollen wir für unser Beispiel beide Gruppen und alle drei Messzeitpunkte berücksichtigen, dann lautat das Modell: Fatigue ~ Gruppe + Zeit. Fatigue wird also durch die Gruppenzugehörigkeit sowie den Messzeitpunkt erklärt. Wir sind also an den Effekten der Variablen Gruppe und Zeit interessiert. Man bezeichnet diese Effekte als Haupteffekte. Schauen wir uns noch einmal den Interaktionsplot an:
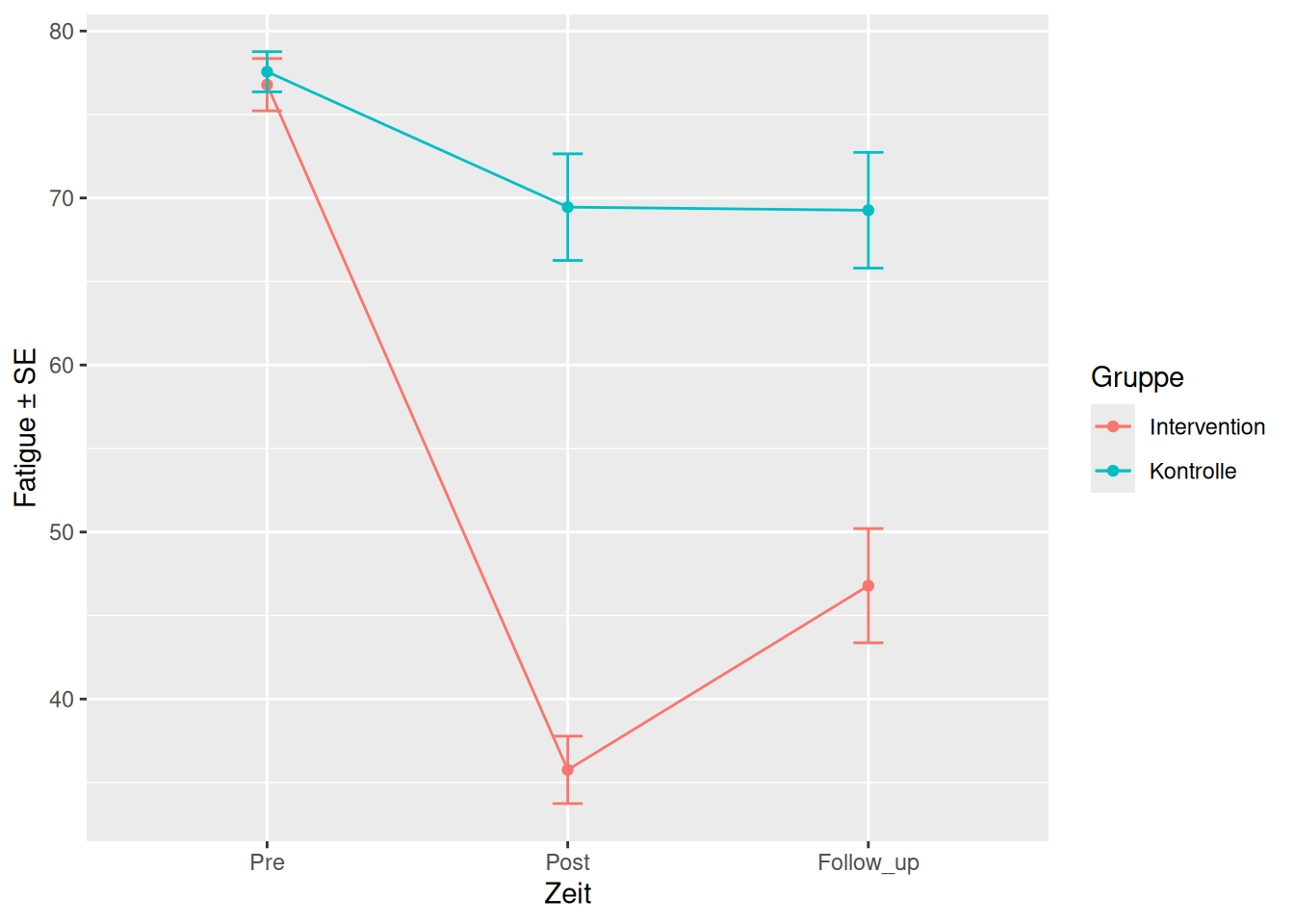
Der Haupteffekt Gruppe bezieht sich auf den Gruppenunterschied unabhängig von der Zeit. Konkret ist der Haupteffekt für Gruppe die Differenz des Mittelwerts der Interventionsgruppe über alle Zeitpunkte und des Mittelwerts der Kontrollgruppe über alle Zeitpunkte. Also im Plot, die Differenz aller roten und aller blauen Werte. Anhand des Plots können wir bereits erahnen, dass die roten Werte durchschnittlich tiefer sind als die blauen. Wir können diesen Unterschied, also den Haupteffekt Gruppe anhand der deskriptiven Werten berechnen:
| Gruppe | Zeit | Mean | SD | n |
|---|---|---|---|---|
| Intervention | Pre | 76.78 | 5.42 | 12 |
| Intervention | Post | 35.76 | 6.99 | 12 |
| Intervention | Follow_up | 46.79 | 11.85 | 12 |
| Kontrolle | Pre | 77.56 | 4.17 | 12 |
| Kontrolle | Post | 69.45 | 11.05 | 12 |
| Kontrolle | Follow_up | 69.27 | 12.00 | 12 |
\[\hat{\mu}_{int} = \frac{1}{3} (76.78 + 35.76 + 46.79) = 53.11,\] \[\hat{\mu}_{con} = \frac{1}{3} (77.56 + 69.45 + 69.27) = 72.09\]
und somit
\[\hat{\mu}_{int} - \hat{\mu}_{con} = 53.11 - 72.09 = -18.98.\] Analog beschreibt der Haupteffekt Zeit den durchschnittlichen Unterschied zwischen den Zeitpunkten über beide Gruppen hinweg (also unabhängig von der Gruppe). Wir haben also:
- \(\hat{\mu}_{Pre} = \frac{76.78 + 77.56}{2} = 77.17\)
- \(\hat{\mu}_{Post} = \frac{35.76 + 69.45}{2} = 52.61\)
- \(\hat{\mu}_{Follow\_up} = \frac{46.79 + 69.27}{2} = 58.03\)
Damit sehen wir:
- \(Pre \to Post\): Abnahme um \(24.5\) Punkte
- \(Pre \to Follow\_up\): Abnahme um \(19.1\) Punkte
- \(Post \to Follow\_up\): Zunahme um \(5.4\) Punkte
Der Output einer entsprechenden multiplen linearen Regression sieht so aus:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 67.68076 2.694482 68 25.118285 3.983309e-36
GruppeKontrolle 18.98279 2.694482 68 7.045061 1.176694e-09
ZeitPost -24.56593 3.300053 68 -7.444101 2.236052e-10
ZeitFollow_up -19.14600 3.300053 68 -5.801725 1.881681e-07Im Modell sehen wir genau diese Werte, die wir oben berechnet haben:
- \(\hat{\beta_0}\) ist in diesem Modell nur schwierig interpretierbar - ignorieren Sie hier das Intercept.
- \(\hat{\beta_1}\) ist der geschätzte Haupteffekte für
Gruppe(die Kontrollgruppe ist im allgemeinen 18.98 Punkte höher). Diesen Wert haben wir oben berechnet. - \(\hat{\beta_2}\) und \(\hat{\beta_3}\) sind die Haupteffekte für
Zeitwie wir sie oben berechnet haben.
Aufmerksame Leser:innen haben sicher gemerkt, dass uns die Information zu den Haupteffekten nicht weiter hilft, wenn wir etwas über die Effektivität der Intervention erfahren wollen. Wie bereits oben ausgeführt, bezieht sich der Haupteffekt Gruppe auf eine Differenz zwischen den Gruppen unabängig vom Zeitpunkt. Wenn die Gruppen z.B. schon zu Beginn unterschiedlich sind, liegt es auf der Hand, dass dieser Effekt - wie hier - statistisch signifikant ist.
Important
Die Haupteffekte zeigen nur den durchschnittlichen Unterschied zwischen Gruppen oder Zeitpunkten insgesamt. Sie sagen nicht, ob sich die Werte über die Zeit in den Gruppen unterschiedlich verändern. Konkret wollen wir wissen, ob der Effekt der Zeit davon abhängt, in welcher Gruppe man ist – das nennt man einen Interaktionseffekt.
16.5 Interaktionseffekte
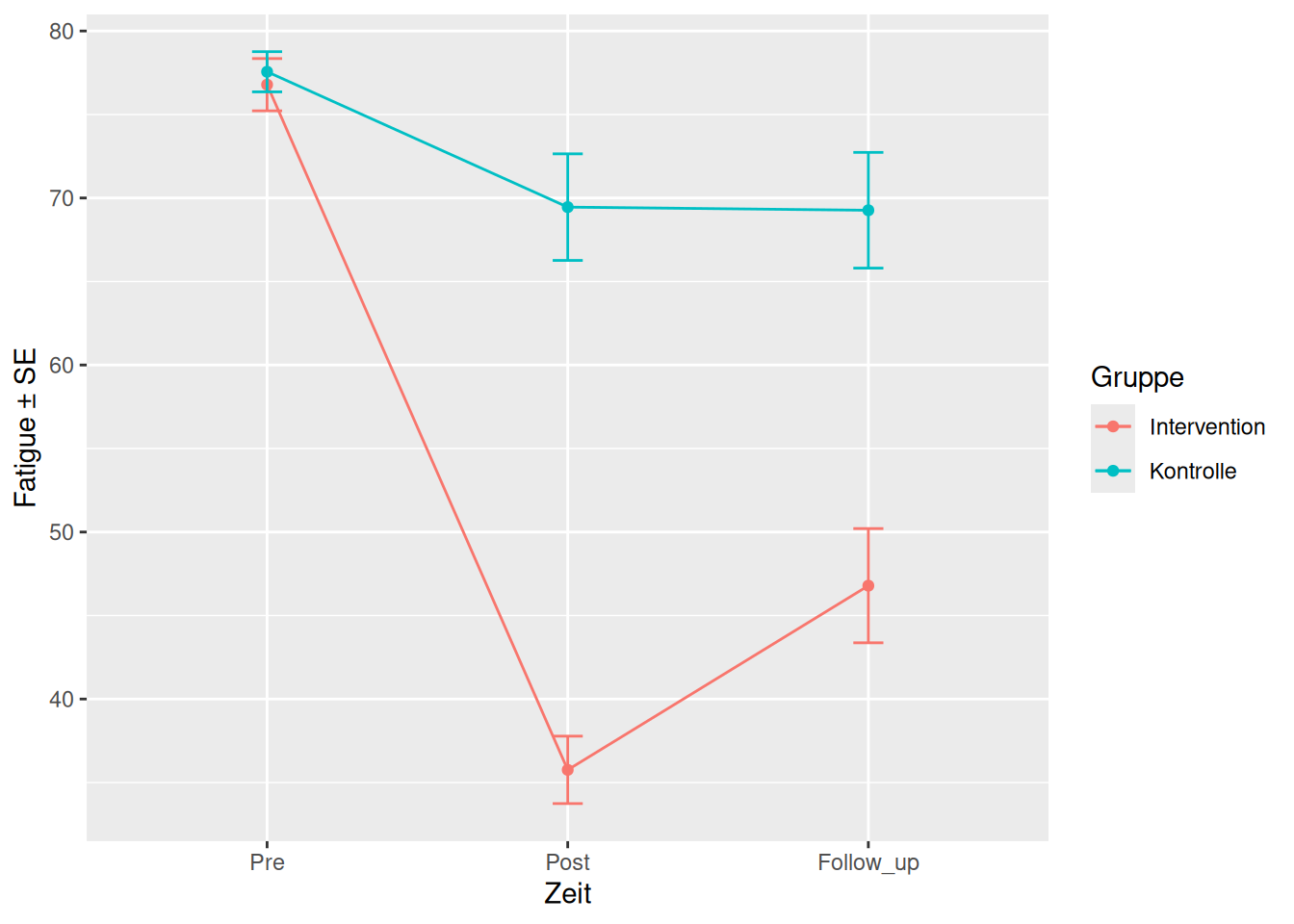
Wie oben ausgeführt, brauchen wir für eine sinnvolle Schlussfolgerung bzgl. der Effektivität der Intervention einen Interaktionseffekt. Ob sich die Werte über die Zeit je nach Gruppe unterschiedlich entwickeln, sieht man im Interaktionsplot (daher der Name), daran, dass die Linien nicht parallel sind.
Important
Merke: Parallele Linien in der Grafik → keine Interaktion. Sind die Linien nicht parallel, muss ein Interaktionseffekt untersucht werden.
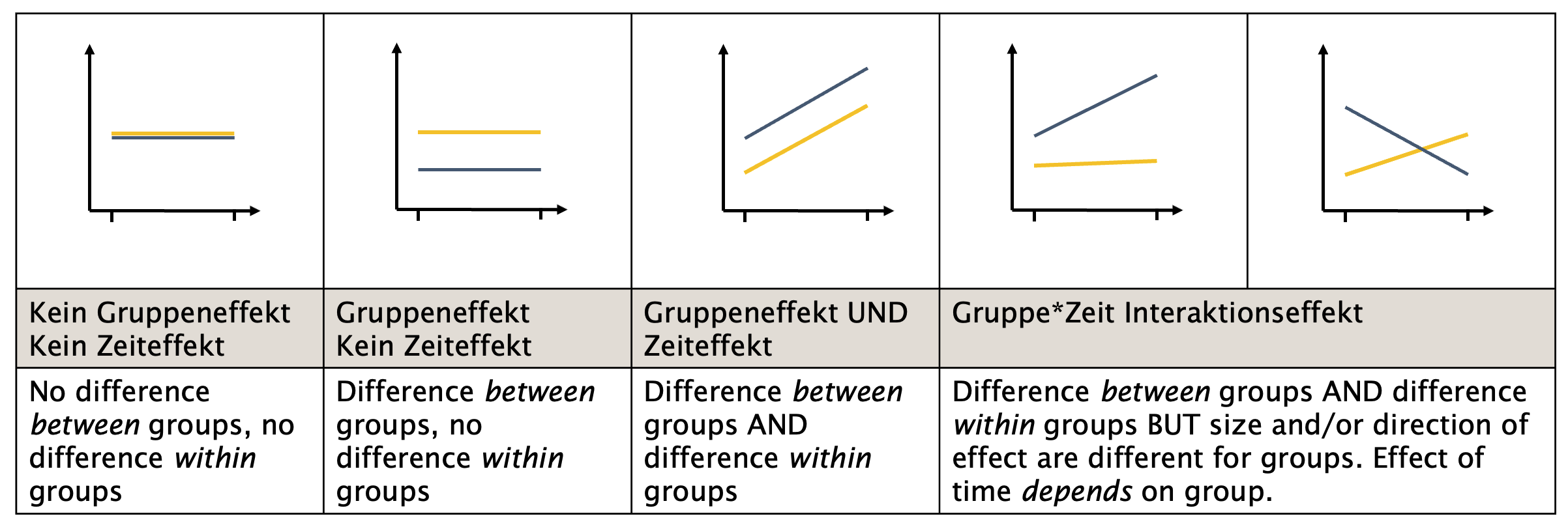
Abbildung 16.7 gibt eine gute Übersicht, wie man zwischen Gruppen-, Zeit- und Interaktionseffekten unterscheiden kann.
Unser Modell lautet jetzt Fatigue ~ Gruppe + Zeit + Gruppe x Zeit, wobei Gruppe x Zeit der Interaktionseffekt ist. Schauen wir uns den Output der Regression zu diesem Modell an:
Estimate Std. Error Pr(>|t|)
(Intercept) 76.7849824 2.641271 4.275908e-39
GruppeKontrolle 0.7743496 3.735321 8.364166e-01
ZeitPost -41.0261269 3.600126 1.021785e-14
ZeitFollow_up -29.9984571 3.600126 1.349812e-10
GruppeKontrolle:ZeitPost 32.9204016 5.091347 6.961820e-08
GruppeKontrolle:ZeitFollow_up 21.7049165 5.091347 1.049233e-04- \(\hat{\beta_0}\) ist der Mittelwert der Interventionsgruppe zum Zeitpunkt
Pre. - \(\hat{\beta_1}\) ist die mittlere Differenz zwischen den Gruppen zum Zeitpunkt
Pre. - \(\hat{\beta_2}\) ist die mittlere Differenz zwischen
PreundPost(unabhängig von der Gruppe!). - \(\hat{\beta_3}\) ist die mittlere Differenz zwischen
PreundFollow_up(unabhängig von der Gruppe!). - \(\hat{\beta_4}\) (Interaktionseffekt) ist die zusätzliche mittlere Differenz zwischen den Gruppen zum Zeitpunkt
Post. - \(\hat{\beta_5}\) (Interaktionseffekt) ist die zusätzliche mittlere Differenz zwischen den Gruppen zum Zeitpunkt
Follow_up.
Durch Einsetzen der Koeffizienten kommen wir auf die entsprechenden Mittelwerte. Was ist der Wert in der Kontrollgruppe zum Zeitpunkt Post?
\[ \begin{aligned} \widehat{Fatigue} &= \hat{\beta_0} + \hat{\beta_1} \times 1 + \hat{\beta_2} \times 1 + \hat{\beta_3} \times 0 + \hat{\beta_4} \times 1 + \hat{\beta_5} \times 0 \\[2mm] &= \hat{\beta_0} + \hat{\beta_1} + \hat{\beta_2} + \hat{\beta_4} \\[1mm] &= 76.78 + 0.77 + (-41.03) + 32.92 \\[1mm] &= 69.44 \end{aligned} \]
Analog können Sie für andere Werte einsetzen. Die Werte stimmen wenig überraschend mit den deskriptiven Werten überein:
| Gruppe | Zeit | Mean | SD | n |
|---|---|---|---|---|
| Intervention | Pre | 76.78 | 5.42 | 12 |
| Intervention | Post | 35.76 | 6.99 | 12 |
| Intervention | Follow_up | 46.79 | 11.85 | 12 |
| Kontrolle | Pre | 77.56 | 4.17 | 12 |
| Kontrolle | Post | 69.45 | 11.05 | 12 |
| Kontrolle | Follow_up | 69.27 | 12.00 | 12 |
Meistens werden in Publikationen P-Werte für die Haupt- und Interaktionseffekte angegeben. Für unser Beispiel sind diese:
Type III Analysis of Variance Table with Satterthwaite's method
Sum Sq Mean Sq NumDF DenDF F value Pr(>F)
Gruppe 5275.3 5275.3 1 22 67.836 3.629e-08 ***
Zeit 7995.4 3997.7 2 44 51.407 3.069e-12 ***
Gruppe:Zeit 3361.3 1680.6 2 44 21.612 2.898e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Wir sehen, dass sowohl die beiden Haupteffekte sowie der Interaktionseffekt statistisch signifikant sind (die P-Werte sind extrem klein). Wir verwerfen also folgende Nullhypothesen:
- \(H_{0_1}\) es gibt keinen Unterschied zwischen den Gruppen.
- \(H_{0_2}\) es gibt keinen Unterschied zwischen den Zeitpunkten.
- \(H_{0_3}\) es gibt keinen Unterschied bzgl. der Veränderung über die Zeit zwischen den Gruppen.
Statistisch gesehen können wir also sagen, dass die Gruppenzugehörigkeit und der Zeitpunkt einen Einfluss auf die Fatige haben (Haupteffekte). Zudem können wir sagen, dass die Fatigue in der Interventionsgruppe über die Zeit mehr abnimmt als in der Kontrollgruppe (Interaktionseffekt, siehe Abbildung 16.6).
16.6 Effektgrössen
Wenn wir die Ergebnisse, oder genauer die Effekte von mehreren Studien zu einem Thema vergleichen wollen, stellt sich oft das Problem, dass das gleiche Outcome auf unterschiedliche Weise gemessen wurde, was die Vergleichbarkeit erschwert. In der Tabelle unten sehen Sie die Kraftwerte von vier Studien bei Schlaganfallpatien:tinnen nach einem Krafttraining (Interventionsgruppe), bzw. bei der Kontrollgruppe. Die Kraftwerte wurden in drei unterschiedlichen Einheiten gemessen (Ada, Dorsch, and Canning 2006).
| Study (unit) | N | Experimental Mean (SD) | N | Control Mean (SD) |
|---|---|---|---|---|
| Duncan (Nm) | 44 | 88.40 (37.40) | 48 | 80.85 (32.00) |
| Lippert-Gruner (N) | 10 | 248.00 (109.25) | 10 | 139.00 (72.75) |
| Merletti (Nm) | 24 | 9.48 (3.28) | 25 | 7.17 (3.62) |
| Winstein (kg/cm) | 20 | 772.86 (666.72) | 20 | 581.75 (538.42) |
Wie können wir die Ergebnisse der vier Studien vergleichen? Welche Studie zeigt den grössten Effekt?
Man kann Effekte, welche auf unterschiedlichen Skalen gemessen wurden, auf eine gemeinsame Skala transformieren. Man nennt dies eine Standardisierung von Effekten. Man kann sowohl within- wie auch between-Effekte standardisieren. Standardisierte Effekte sind dimensionslos, infolgedessen können Ergebnisse, die in unterschiedlichen Einheiten gemessen wurden, miteinander verglichen werden. Abhängig von der Art der Analyse und der Skalierung der Zielvariable, gibt es verschiedene Möglichkeiten für standardisierte Effekte:
- Standardisierte mittlere Differenz bzw. standardisierte Mittelwertsdifferenz (SMD)
- Korrelationskoeffizient
- Quotenverhältnis (Odds Ratio)
- Risk Ratio
- …
Während Korrelationskoeffizienten, Odds Ratios und Risk Ratios bereits standardisiert sind, muss die SMD (auch Cohen’s \(d\)) zusätzlich berechnet werden. Wir erwarten nicht, dass Sie selber standardisierte Effekte berechnen, sondern, dass Sie diese korrekt interpretieren (siehe Lernziele). Für Interessierte:
\[ SMD = \frac{\bar{X}_{exp} - \bar{X}_{con}}{S_{pooled}} \]
wobei
\[ S_{pooled} = \sqrt{\frac{(n_{exp} - 1)S_{exp}^2 + (n_{con} - 1)S_{con}^2}{n_{exp} + n_{con} - 2}}. \]
Legende:
- \(\bar{X}_{exp}\) = Mittelwert der Experimentalgruppe
- \(\bar{X}_{con}\) = Mittelwert der Kontrollgruppe
- \(S_{exp}\) = Standardabweichung der Experimentalgruppe
- \(S_{con}\) = Standardabweichung der Kontrollgruppe
- \(n_{exp}\) = Stichprobengrösse der Experimentalgruppe
- \(n_{con}\) = Stichprobengrösse der Kontrollgruppe
- \(S_{pooled}\) = gepoolte Standardabweichung
Tip
Ein praktisches Tool für die Berechnung von Effektgrössen ist das Online-Tool http://www.psychometrica.de/effektstaerke.html. Damit Sie damit Effektgrössen berechnen können, brauchen Sie aus den Studien die ersten 6 Kennwerte der Legende oben.
16.6.1 Interpretation von SMD
Da wir anhand der Standardabweichung standardisieren, ist die Einheit von SMD “Standardabweichungen”. SMD misst also die Grösse eines Effekts, indem es den Unterschied zwischen zwei Mittelwerten in Einheiten der Standardabweichung ausdrückt. Damit wird der Unterschied „standardisiert“, sodass man ihn unabhängig von der ursprünglichen Skala interpretieren kann. Eine SMD von 0.5 bedeutet somit, dass die Interventionsgruppe 0.5 Standardabweichungen “besser” oder “schlechter” ist als die Kontrollgruppe.
Als allgemeine Fausregel gilt:
- \(SMD \approx 0.2\) → kleiner Effekt
- \(SMD \approx 0.5\) → mittlerer Effekt
- \(SMD \approx 0.8\) → grosser Effekt
Manche Fachbereiche haben aber eigene Konventionen, wann ein Effekt “gross” oder “klein” ist. Deshalb sollte man die Werte immer im Kontext interpretieren und die entsprechende Literatur konsultieren.
Die Tabelle unten ist nun ergänzt mit den entsprechenden SMD’s. Sie können diese mit Hilfe von Psychometrica nachrechnen. Wie zu allen geschätzten Parametern sollte zusätzlich zur Effektgröse ein 95% Konfidenzintervall angegeben werden. Daran erkennen Sie, dass in der Tabelle unten nur zwei der vier berechneten Effekgrössen statistisch signifikant verschieden von 0 sind.
| Study | N (Exp) | Mean (Exp) | SD (Exp) | N (Ctrl) | Mean (Ctrl) | SD (Ctrl) | SMD (Cohen’s d) | 95% CI |
|---|---|---|---|---|---|---|---|---|
| Duncan (Nm) | 44 | 88.40 | 37.40 | 48 | 80.85 | 32.00 | 0.218 | [-0.20, 0.63] |
| Lippert-Gruner (N) | 10 | 248.00 | 109.25 | 10 | 139.00 | 72.75 | 1.174 | [0.23, 2.12] |
| Merletti (Nm) | 24 | 9.48 | 3.28 | 25 | 7.17 | 3.62 | 0.668 | [0.10, 1.24] |
| Winstein (kg/cm) | 20 | 772.86 | 666.72 | 20 | 581.75 | 538.42 | 0.315 | [-0.31, 0.94] |
16.6.2 Weitere Effektgrössen
In der Tabelle unten finden Sie weitere gängige Effektgrössen in der Übersicht. Wenn Sie eine Effektgrösse, z.B. für die Bachelorthese, verwenden möchten oder zu einer Effektgrösse mehr Informationen benötigen, wenden Sie sich bitte an Ihre:n Referent:in.
| Effektgrösse | Erläuterung |
|---|---|
| \(RD\) | Risk Difference: Unterschied der Wahrscheinlichkeit für ein bestimmtes Outcome zwischen zwei Gruppen |
| \(RR\) | Risk Ratio: Vergleicht die Wahrscheinlichkeit für ein Ereignis in der einen Gruppe mit der Wahrscheinlichkeit in einer anderen Gruppe |
| \(OR\) | Odds Ratio: Vergleicht die Odds für ein Ereignis in der einen Gruppe mit den Odds in einer anderen Gruppe |
| \(d\) | Cohen‘s d: Standardisierte Mittelwertsdifferenz zwischen zwei Gruppen, basierend auf der gepoolten Standardabweichung. Cohen‘s d von 0.2, 0.5 und 0.8 entspricht einem kleinen, mittleren und starken Effekt. |
| \(\Delta\) | Glass‘s Delta: Standardisierte Mittelwertsdifferenz zwischen zwei Gruppen, basierend auf der Standardabweichung der Kontrollgruppe |
| \(g\) | Hedges‘ g: Standardisierte Mittelwertsdifferenz zwischen zwei Gruppen, basierend auf der gepoolten und gewichteten Standardabweichung |
| \(\rho\) | Pearson‘s Korrelationskoeffizient: Wird verwendet, wenn beide Variablen quantitativ sind |
| \(\rho\) | Spearman‘s rho (Rangkorrelationskoeffizient): Wird verwendet, wenn beide Variablen ordinal sind |
| \(\tau\) | Kendall‘s Tau: Wird ähnlich wie der Rangkorrelationskoeffizient verwendet |
| \(R^2\) | Bestimmtheitsmass: Gibt den prozentualen Anteil der Variabilität der abhängigen Variablen an, der durch die unabhängige Variable erklärt wird |
| adj. \(R^2\) | Adjusted R²: Korrigiertes Bestimmtheitsmass für ein multiples Regressionsmodell; berücksichtigt Stichprobenumfang und Anzahl der Prädiktoren |
| \(\eta^2\) | Eta-Quadrat: Korrelationsverhältnis, üblicherweise für ANOVA verwendet. Verwandt mit R²: gibt an, wie gross der Anteil an der Gesamtvarianz in der abhängigen Variable ist, der durch die unabhängige Variable erklärt werden kann. Ein partielles Eta-Quadrat von .01, .06 und .14 entspricht einem kleinen, mittleren und grossen Effekt. |