14 Diagnostikstudien
Alle Messinstrumente haben einen Messfehler. Wenn man das weiss, sind manche trotzdem brauchbar.
Dieses Kapitel ist zu einem guten Teil eine nostalgische Reise zurück ins erste Semester und daher Repetition. Einige Aspekte, insbesondere die Risk-of-Bias-Analyse von Diagnostikstudien, bekommen hier jedoch ein Upgrade und werden gründlicher unter die Lupe genommen.
14.1 Wozu Diagnostikstudien?
Es geht im Gegenstandsbereich der Diagnostik um Verfahren, mit denen wir den Gesundheitsstatus von Patient:innen erfassen und quantifizieren, um diese Daten in den klinischen Denkprozess zu integrieren. Zu diesen Verfahren zählen alle diagnostischen und evaluativen Messmethoden wie z. B. klinische Tests, Messinstrumente oder Fragebögen. Wir verwenden in diesem Kapitel dafür den Überbegriff Assessments.
Assessments spielen eine zentrale Rolle in der physiotherapeutischen Praxis und Forschung. Sie bilden die Grundlage für Diagnosen, Prognosen und die Evaluation der Therapie. Entscheidend ist, dass die verwendeten Assessments passend und zuverlässig sind und deren Resultate korrekt interpretiert werden.
Für das Schreiben dieses Kapitels habe ich mich teilweise vom Buch Measurement in Medicine inspirieren lassen. Interessierten kann ich dieses Buch nur empfehlen, Sie erhalten es via BFH-Login gratis hier.
Important
- Wer Resultate von Assessments falsch interpretiert, kann keine korrekte Diagnose stellen.
- Wer Resultate von Assessments falsch interpretiert, kann keine adäquate Therapieplanung vornehmen.
- Wer Resultate von Assessments falsch interpretiert, kann nicht evaluieren, ob eine Intervention effektiv war oder nicht.
Im Kontext der Physiotherapie gibt es eine Vielzahl an verschiedenen Assessments und es werden laufend neue entwickelt. Allerdings sind viele dieser Assessments unzureichend validiert und demnach für den Einsatz in der Praxis nicht geeignet. Dieses Kapitel dient als Leitfaden, um wichtige Eigenschaften bestehender Assessments zu bewerten. Ziel ist es, dass Sie zwischen schlecht und gut validierten Assessments unterscheiden können und dass Sie die Resultate von Assessments korrekt interpretieren.
Das Feld der Physiotherapie ist extrem vielfältig. Sie behandeln zahlreiche Krankheiten, und Gesundheit bedeutet weit mehr als die blosse Abwesenheit von Krankheit. Die Weltgesundheitsorganisation (WHO) definiert Gesundheit als „einen Zustand vollkommenen körperlichen, geistigen und sozialen Wohlbefindens und nicht nur als Abwesenheit von Krankheit oder Gebrechen“. Entsprechend vielfältig sind die physiotherapeutischen Assessments.
In der klinischen Praxis umfasst die Evaluation von Behandlungen und die Überwachung des Krankheitsverlaufs viele Aspekte: die Erfassung des Krankheitsstadiums, die Schwere der Beschwerden und die gesundheitsbezogene Lebensqualität (QoL). Zusätzlich zu den Ergebnismessungen zählen auch alle Assessments, die zur Diagnosestellung und Prognosebewertung durchgeführt werden. Diese Assessments finden sowohl in der Forschung als auch im klinischen Alltag Anwendung.
Die Vielfalt der Assessments spiegelt sich in den verschiedenen Messmethoden wider. Sie reicht von Fragen zu Symptomen während der Anamnese über körperliche Untersuchungen bis hin zu spezifischen, strukturellen Tests.
Lernziele
Die Studierenden …
- können zentrale statistische Kennwerte der Diagnostik, darunter Sensitivität, Spezifität, Vor- und Nachtestwahrscheinlichkeit, Kappa, ICC, MDC und MCID differenzieren und interpretieren.
- können Sensitivität, Spezifität anhand einer Vierfeldertabelle berechnen.
- können Nachtestwahrscheinlichkeiten (prädiktive Werte) unter Berücksichtigung einer Vortestwahrscheinlichkeit, Sensitivität und Spezifität berechnen.
- können MDC und MCID auf Basis von Studienresultaten interpretiere deren Bedeutung bestimmen.
- können zentrale Erkenntnisse zur Reliabilität anhand eines Bland-Altman-Plots, eines ICC-Wertes oder eines Kappa-Wertes erläutern, ohne diese selbst berechnen zu müssen.
- können die methodischen Herausforderungen, die mit dem Einsatz des Korrelationskoeffizienten bei Reliabilitätsuntersuchungen verbunden sind, erklären.
- können den Zweck und die Zielsetzung einer Risk-of-Bias-Analyse im Kontext von Diagnostikstudien beschreiben.
- können mithilfe der COSMIN-Checkliste das Risiko für zentrale Biastypen in Diagnostikstudien einschätzen.
14.2 Terminologie
In der Fachliteratur zu Assessments herrscht oft Verwirrung durch die Vielzahl unterschiedlicher Begriffe und Definitionen. Häufig werden für dieselbe Eigenschaft verschiedene Synonyme verwendet. So wird z. B. die Messqualität “Reliabilität” auch als Reproduzierbarkeit, Stabilität, Wiederholbarkeit oder Präzision bezeichnet. Diese Vielfalt in Terminologie und Definitionen war ein Grund für die Durchführung einer internationalen Delphi-Studie, um konsensbasierte Standards zur Auswahl von Assessments im Gesundheitsbereich zu entwickeln: die COSMIN-Studie (Mokkink et al. 2010). Wir verwenden die Terminologie dieser COSMIN-Studie. Wie Sie oben bereits erfahren haben, verwenden wir den Begriff Assessments als Überbegriff für verschiedene Messinstrumente. Das können klinische Tests wie z. B. ein Schubladentest sein, Messinstrumente wie z. B. der Goniometer, Fragebögen wie z. B. der “Quality of Life Questionnaire” oder Scores/Skalen wie z. B. die visuelle Analogskala.
14.3 Messkonzepte, Messtheorien und Messmodelle
In diesem Abschnitt gehen wir genauer darauf ein, in welchen verschiedenen Gebieten und zu welchen verschiedenen Zwecken Assessments eingesetzt werden. Die folgende Tabelle fasst wichtige Begriffe zusammen:
| Begriff | Erklärung |
|---|---|
| Concept | Ein gut definierter und präzise abgegrenzter Messgegenstand. |
| Construct | Von Psychologen verwendeter Begriff für nicht-beobachtbare Merkmale wie Intelligenz, Depression oder gesundheitsbezogene Lebensqualität. |
| Measurement model (macro-level) | Theoretisches Modell, wie verschiedene Konstrukte innerhalb eines Konzepts miteinander in Beziehung stehen (z. B. das Wilson- und Cleary-Modell des Gesundheitsstatus). |
| Measurement model (micro-level) | Ein Modell, das die Beziehungen zwischen den Items und dem zu messenden Konstrukt darstellt (z. B. reflektives oder formatives Modell). |
| Measurement theory | Eine Theorie darüber, wie die durch Items generierten Scores das zu messende Konstrukt repräsentieren (z. B. klassische Testtheorie oder Item-Response-Theorie). |
| Method of measurement | Methode der Datenerhebung oder Art des Messinstruments (z. B. Bildgebungstechniken, biochemische Analysen, Leistungstests, Interviews). |
| Patient-reported outcomes | Eine Messung von Aspekten des Gesundheitszustands von Patient:innen, die direkt von Patient:innen selbst stammen, ohne Interpretation der Antworten durch eine andere Personen. |
| Non-patient-reported outcome measurement instruments | Alle anderen Arten von Assessments (z. B. Arztberichte, Bildgebungstechniken, biochemische Analysen oder leistungsbasierte Tests). |
| Health-related quality of life | Die Wahrnehmung eines Individuums, wie eine Krankheit und deren Behandlung die physischen, mentalen und sozialen Aspekte seines Lebens beeinflussen. |
Wir verwenden als Beispiel das Messmodell (Makroebene) zur Lebensqualität, welches von Wilson und Cleary entwickelt wurde (Wilson and Cleary 1995).
14.3.1 Eigenschaften von Assessemnts
Krankheitsspezifische und generische Assessments
Wir unterscheiden zwischen generischen und krankheitsspezifischen Assessments. Generische Assessments sind breit anwendbare Messinstrumente, die Aspekte der allgemeinen Funktionsfähigkeit, Lebensqualität und Gesundheit erfassen, unabhängig von einer spezifischen Erkrankung. Beispiele hierfür sind die VAS zur Schmerzbewertung oder ein Gesundheitsfragebogen. Diese Instrumente bieten eine umfassende Sicht auf den Gesundheitsstatus der Patient:innen und können auf der rechten Seite des Wilson-Cleary-Modells, insbesondere in den Bereichen “wahrgenommene Gesundheit” und QoL angewendet werden.
Krankheitsspezifische Assessments hingegen konzentrieren sich auf die Bewertung von Aspekten, die direkt mit einer bestimmten Erkrankung oder einem bestimmten Krankheitsbild zusammenhängen. Sie messen gezielt die Auswirkungen einer spezifischen Krankheit, z. B. auf den funktionellen Status. Solche Instrumente sind oft präziser in der Beurteilung von Krankheitsverläufen und werden typischerweise auf der linken Seite des Wilson-Cleary-Modells verwendet, da sie eng mit der Diagnose und den pathophysiologischen Aspekten einer Krankheit verknüpft sind.
Beide Assessment-Typen ergänzen sich und bieten eine ganzheitliche Sicht auf die Gesundheit der Patient:innen, wobei generische Assessments breitere Gesundheitsaspekte und krankheitsspezifische Assessments spezifische Krankheitsmerkmale fokussieren. Wie so oft bestätigen Ausnahmen die Regel.
Diagnose- und Outcome-Assessments
Bei der Diagnose einer Krankheit konzentrieren wir uns oft auf die linke Seite des Wilson-Cleary-Modells (Abbildung 14.1), während bei der Evaluation von Krankheits- oder Behandlungsergebnissen die rechten Bereiche des Modells relevanter sind. Die Diagnose vieler Krankheiten basiert auf morphologischen Veränderungen im Gewebe, Störungen in physiologischen Prozessen oder pathophysiologischen Befunden. Ein hoher Blutzuckerspiegel ist zum Beispiel ein spezifischer Indikator für Diabetes, da er eine Funktionsstörung in der Insulinproduktion widerspiegelt. Andere Krankheiten wie Migräne oder Depression können nur anhand ihrer Symptome diagnostiziert werden.
Der funktionelle Status wird häufig als Ergebnis einer Krankheit betrachtet. In der Physiotherapie und Rehabilitation jedoch wird der funktionelle Status oft auch als Diagnose angesehen, da die Behandlung auf der Verbesserung der Funktionalität abzielt. Weiter rechts im Modell befinden sich die wahrgenommene Gesundheit und die QoL, die in der Regel als Outcome-Messungen gelten. Dennoch können auch Krankheitsverläufe anhand von Parametern auf der linken Seite des Modells bewertet werden. Zum Beispiel wird der Effekt von Krebstherapien auf das Wachstum von Krebszellen meist anhand von morphologischen oder biochemischen Parametern auf Gewebeebene bewertet.
Wie Sie sehen, habe ich in Abbildung 14.1 reingeschrieben: Zu einem gewissen Masse kann man Assessments den ICF Kategorien Struktur, Funktion und Partizipation zuweisen.
Physiotherapeut:innen-basierte und Patient:innen-basierte Assessments
Messungen, die von Physiotherapeut:innen oder von den Patient:innen selbst durchgeführt werden, befinden sich an unterschiedlichen Stellen im Wilson-Cleary-Modell (Abbildung 14.1). Messungen von Aspekten auf der linken Seite des Modells, sei es zur Diagnose oder zur Outcome-Evaluation, werden in der Regel von Physiotherapeut:innen vorgenommen. So können beispielsweise Zeichen wie eine Schwellung von Physiotherapeut:innen erfasst werden, während Symptome wie Schmerzen nur von den Patient:innen selbst berichtet werden können. Die Beurteilung der Funktionsfähigkeit kann sowohl durch Physiotherapeut:innen als auch durch die Patient:innen selbst erfolgen. Physiotherapeut:innen verwenden häufig standardisierte Leistungstests, um die körperliche Funktionsfähigkeit zu bewerten. Alternativ kann die Funktionsfähigkeit auch mithilfe eines Fragebogens beurteilt werden, in dem die Patient:innen gefragt werden, inwieweit sie bestimmte Aktivitäten ausführen können. Wenn Informationen direkt von den Patient:innen erfasst werden, sprechen wir von Patient-Reported-Outcomes (PROs). PROs werden definiert als jede Art von Messung, die direkt von Patient:innen kommt, wie sie in Bezug auf eine Gesundheitsstörung und deren Therapie funktionieren oder sich fühlen, ohne dass eine Interpretation der Antworten durch Physiotherapeut:innen erfolgt. Symptome, wahrgenommene Gesundheit und QoL sind Aspekte des Gesundheitsstatus, die nur durch PROs bewertet werden können, da sie die Einschätzung und Wahrnehmung der Patient:innen zu ihrem aktuellen Gesundheitszustand betreffen. Daher besteht die rechte Seite des Wilson-Cleary-Modells ausschliesslich aus PROs (Abbildung 14.1).
Objektive und subjektive Assessments
Die Begriffe “objektiv” und “subjektiv” sind schwer zu definieren, da es vor allem um die Beteiligung persönlicher Urteile geht. Bei objektiven Messungen sind keine persönlichen Einschätzungen involviert, das heisst, weder die Person, die misst, noch die Patient:innen, die gemessen werden, können das Ergebnis durch persönliche Urteile beeinflussen. Subjektive Messungen hingegen erlauben es entweder den Patient:innen oder der durchführenden Person, das Ergebnis in gewissem Masse zu beeinflussen.
Die Bewertung der wahrgenommenen Gesundheit und der QoL erfordert subjektive Messungen, während die Messung eines Gelenkwinkels in der Regel objektive Messungen darstellen. Objektive Messungen finden sich meist auf der linken Seite des Wilson-Cleary-Modells, in den Bereichen biologischer und physiologischer Variablen (Abbildung 14.1). Symptome sind per Definition subjektive Messungen, da sie nur von den Patient:innen selbst wahrgenommen werden. Ein Symptom wird als eine Abweichung von der normalen Funktion oder dem normalen Gefühl definiert, die von den Patient:innen bemerkt wird und auf das Vorhandensein einer Krankheit oder Anomalie hinweist. Ein “klinisches Zeichen” ist dagegen eine objektive medizinische Beobachtung, die von Physiotherapeut:innen während einer körperlichen Untersuchung erkannt werden kann, wie zum Beispiel eine Schwellung des Knöchels.
Der Unterschied zwischen objektiven und subjektiven Messungen ist jedoch nicht immer eindeutig, und viele Messungen werden fälschlicherweise als objektiv bezeichnet. Zum Beispiel erfordert die Interpretation vieler bildgebender Tests eine klinische Fachkraft, welche die Bilder liest und interpretiert. Auch die Beurteilung des Schwellungsgrades eines Knöchels ist subjektiv. Labortests verlieren an Objektivität, wenn etwa der Analyst die Farbe einer Urinprobe beurteilen muss. Diese Beispiele zeigen, dass viele Testergebnisse durch Beobachten, Hören, Riechen usw. interpretiert werden müssen, was die Sinnesorgane der klinischen Fachkraft einbezieht. All diese Messungen enthalten daher einen subjektiven Aspekt.
Auch bei einem körperlichen Leistungstest müssen die Instruktionen durch die Physiotherapeutin oder den Physiotherapeuten gegeben werden, und das Mass an verbaler Unterstützung kann stark variieren. In kognitiven oder physischen Leistungstests können die Instruktionen und die Unterstützung durch die durchführende Person die Motivation und Konzentration der Patient:innen beeinflussen. Hier wird durch die Person, die die Messung anleitet, ein subjektiver Einfluss auf die Leistung der Patient:innen eingeführt. Daher finden wir auch subjektive Messungen auf der linken Seite des Wilson-Cleary-Modells (Abbildung 14.1). Objektive Messungen sind subjektiven Assessments nicht zwingend überlegen.
Assessments für beobachtbare und nicht-beobachtbare Merkmale
Wenn man im Wilson-Cleary-Modell von links nach rechts geht, kann man zwischen der Messung von beobachtbaren und nicht-beobachtbaren Merkmalen unterscheiden. Viele biologische und physiologische Variablen werden durch direkte Messung erfasst. Ein Beispiel hierfür ist die Gelenkbeweglichkeit, welche mithilfe eines adäquaten Instruments direkt beobachtet werden kann. Allerdings finden wir bei Symptomen und im funktionellen Status bereits nicht-beobachtbare Merkmale, wie zum Beispiel Schmerzen, Müdigkeit und mentale Funktionsfähigkeit. Wahrgenommene Gesundheit und die QoL sind ebenfalls nicht-beobachtbare Konstrukte.
Um diese nicht-beobachtbaren Merkmale zu messen, muss eine neue Strategie entwickelt werden. Es überrascht nicht, dass Psycholog:innen in der Entwicklung von Methoden zur Messung nicht-beobachtbarer Merkmale sehr aktiv waren, da diese in ihrem Fachgebiet häufig vorkommen. Diese nicht-beobachtbaren Merkmale werden als “Konstrukte” bezeichnet. Sie entwickelten Strategien, die es ermöglichen, diese nicht-beobachtbaren Konstrukte indirekt zu messen: Man erfasst beobachtbare Merkmale, die mit den nicht-beobachtbaren Konstrukten in Beziehung stehen.
Diskriminierende, prädiktive und evaluative Assessments
Wir unterscheiden zwischen diskriminierenden, prädiktiven und evaluativen Assessments. Diskriminierende Assessments dienen dazu, Unterschiede zwischen Patientengruppen zu identifizieren, etwa ob eine Einschränkung oder ein spezifischer Gesundheitszustand vorliegt. Sie helfen z. B. festzustellen, ob jemand eine bestimmte Bewegungsstörung hat oder eben nicht. Prädiktive Assessments werden genutzt, um die Wahrscheinlichkeit eines zukünftigen Ereignisses oder Krankheitsverlaufs abzuschätzen, wie z. B. das Risiko eines erneuten Sturzes bei älteren Patient:innen. Evaluative Assessments schliesslich messen Veränderungen im Gesundheitszustand über die Zeit, wie Fortschritte in der Beweglichkeit nach einer therapeutischen Intervention. Zusammen ermöglichen diese drei Typen eine umfassende Einschätzung und Unterstützung von Diagnose, Prognose und Therapieevaluation in der Physiotherapie.
Reflektive und formative Messmodelle
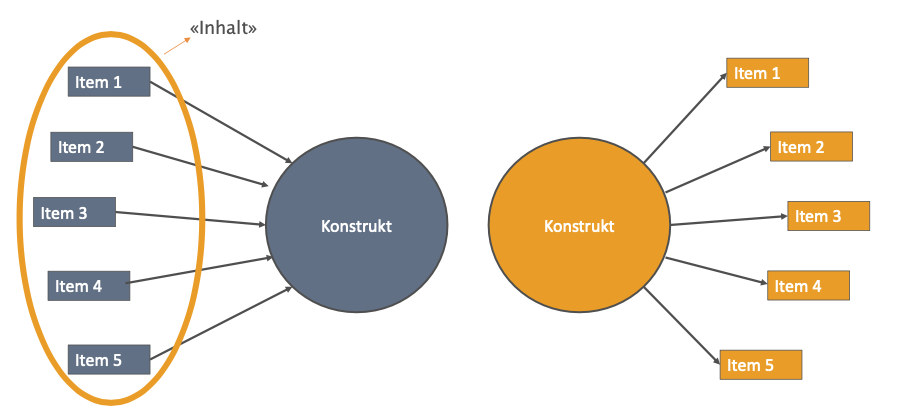
Bei der Messung von Konstrukten müssen wir die zugrunde liegende Beziehung zwischen den einzelnen messbaren Merkmalen und dem nicht-messbaren Konstrukt verstehen. Diese zugrunde liegende Beziehung bezeichnen wir als konzeptionelles Modell. Wir kürzen etwas ab und schauen uns nur die zwei einfachsten Formen solcher Beziehungen an. Dies zwei Formen sehen Sie in Abbildung 14.2. Im konzeptionellen Modell auf der rechten Seite manifestiert sich das Konstrukt in den messbaren Items; anders ausgedrückt: das Konstrukt wird durch diese Items reflektiert. Dieses Modell wird als reflexives Modell bezeichnet (Edwards and Bagozzi 2000). Das linke Modell in Abbildung 14.2 repräsentiert ein formatives Modell. Wie man anhand der Pfeile erkennt, formen die verschiedenen Items das Konstrukt. Die Abbildung 14.3 zeigt zwei konkrete Beispiele für ein reflektives und ein formatives Modell:
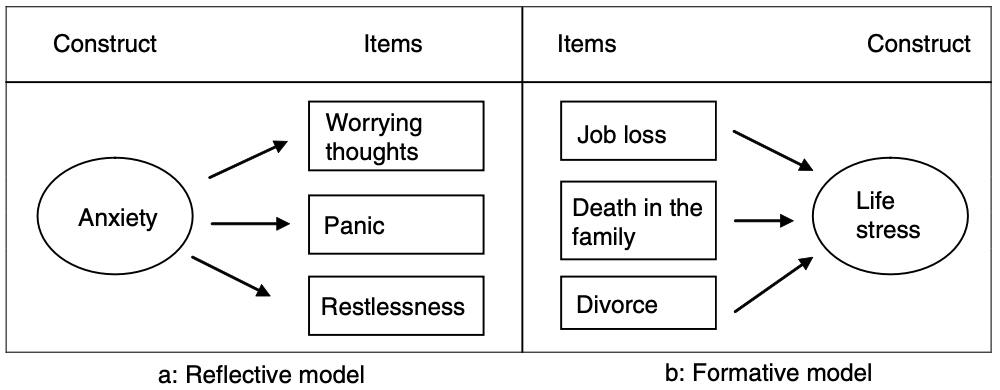
Wie können wir entscheiden, ob die Beziehung zwischen Items und Konstrukt auf einem reflexiven oder einem formativen Modell basiert? Der einfachste Weg, dies herauszufinden, ist ein Gedankenexperiment: Erwarten wir, dass sich die Items ändern, wenn sich das Konstrukt ändert? Dies ist der Fall bei Angst, jedoch nicht unbedingt bei Lebensstress. Wenn beispielsweise eine Person ihren Job verliert, wird der Lebensstress wahrscheinlich zunehmen. Wenn der Lebensstress jedoch zunimmt, verliert eine Person nicht zwangsläufig ihren Job. Wenn eine Änderung des Konstrukts nicht alle Items beeinflusst, ist das zugrunde liegende Modell wahrscheinlich formativ. Bei Angst jedoch: Wenn ein Patient ängstlicher wird, würden wir erwarten, dass sich die Werte aller Items erhöhen. Der Patient wird mehr in Panik geraten, zunehmend unruhig werden und auch mehr besorgte Gedanken haben. Wenn eine Änderung des Konstrukts alle Items beeinflusst, ist das zugrunde liegende Modell reflexiv. Bei reflektiven Modellen erwarten wir, dass die Items zu einem bestimmten Grad zusammenhängen: Wenn jemand öfters in Panik geratet, ist diese Person vermutlich auch öfters unruhig. Bei formativen Modellen ist das nicht der Fall (wenn Sie sich von Ihrem Mann trennen, müssen Sie ihn ja nicht gleich umbringen 🙃).
Die Chronologie des Wilson-Cleary-Modells kann uns teilweise dabei helfen, das konzeptionelle Modell zu bestimmen. Die Messung von Symptomen und funktionellen Einschränkungen, die eine Folge der Krankheit sind, folgt normalerweise eher einem reflexiven Modell, während die Messung der Auswirkungen dieser Symptome und funktionellen Einschränkungen auf die allgemeine wahrgenommene Gesundheit (QoL) in der Regel einem formativen Modell folgt.
14.4 Gütekriterien von Assessments
Nachdem Sie nun einen Einblick in die allgemeine Messtheorie erhalten haben, widmen wir uns der zentralen Frage: Wenn wir anhand eines Assessments ein Merkmal erheben, entspricht das Ergebnis der Wahrheit?
Eine Antwort darauf geben uns die sogenannten Gütekriterien von Assessments. Gütekriterien sind wie ein Gütesiegel für Assessments. Wenn alle Gütekriterien in ausreichendem Masse erfüllt sind, können wir ziemlich sicher sein, dass ein gemessener Wert dem wahren Wert entspricht. Mathematisch könnten wir das so formulieren:
\[ X_i = T_i + E_i, \]
wobei \(X_i\) der gemessene Wert der \(i\)-ten Person, \(T_i\) der wahre Wert und \(E_i\) der Messfehler bei der \(i\)-ten Person ist. Der Index \(i\) läuft dabei von 1 bis \(n\), wobei \(n\) die Anzahl der beobachteten Personen bezeichnet.
Anders als in der klassichen Statistik gibt bzgl. \(E_i\) keine Annahme wie z.B. eine Normalverteilung um 0. Es gilt also nicht zwingend \(E \sim \mathcal{N}(0, \sigma^2)\), das bedeutet, \(E\) kann systematisch unterschiedlich von 0 sein!
Wie Sie ganz am Anfang des Kapitels erfahren haben, ist jedes Assessment mit einem gewissen Messfehler \(E\) verbunden. Das mag auf den ersten Blick frustrierend sein. Wenn wir uns dessen aber bewusst sind, können wir Assessments dennoch effektiv und gewinnbringend einsetzen. Wenn wir aber gemessenen Werten blind vertrauen, kann ganz viel schief gehen; das Messen von Merkmalen ist dann reine Zeitverschwendung.
Wir unterscheiden drei wesentliche Gütekriterien:
- Reliabilität
- Responsivität
- Validität
Jedes Kriterium ist wiederum in Unterkategorien unterteilt. Abbildung 14.4 gibt einen entsprechenden Überblick. Im Folgenden gehen wir detaillierter auf diese ein.
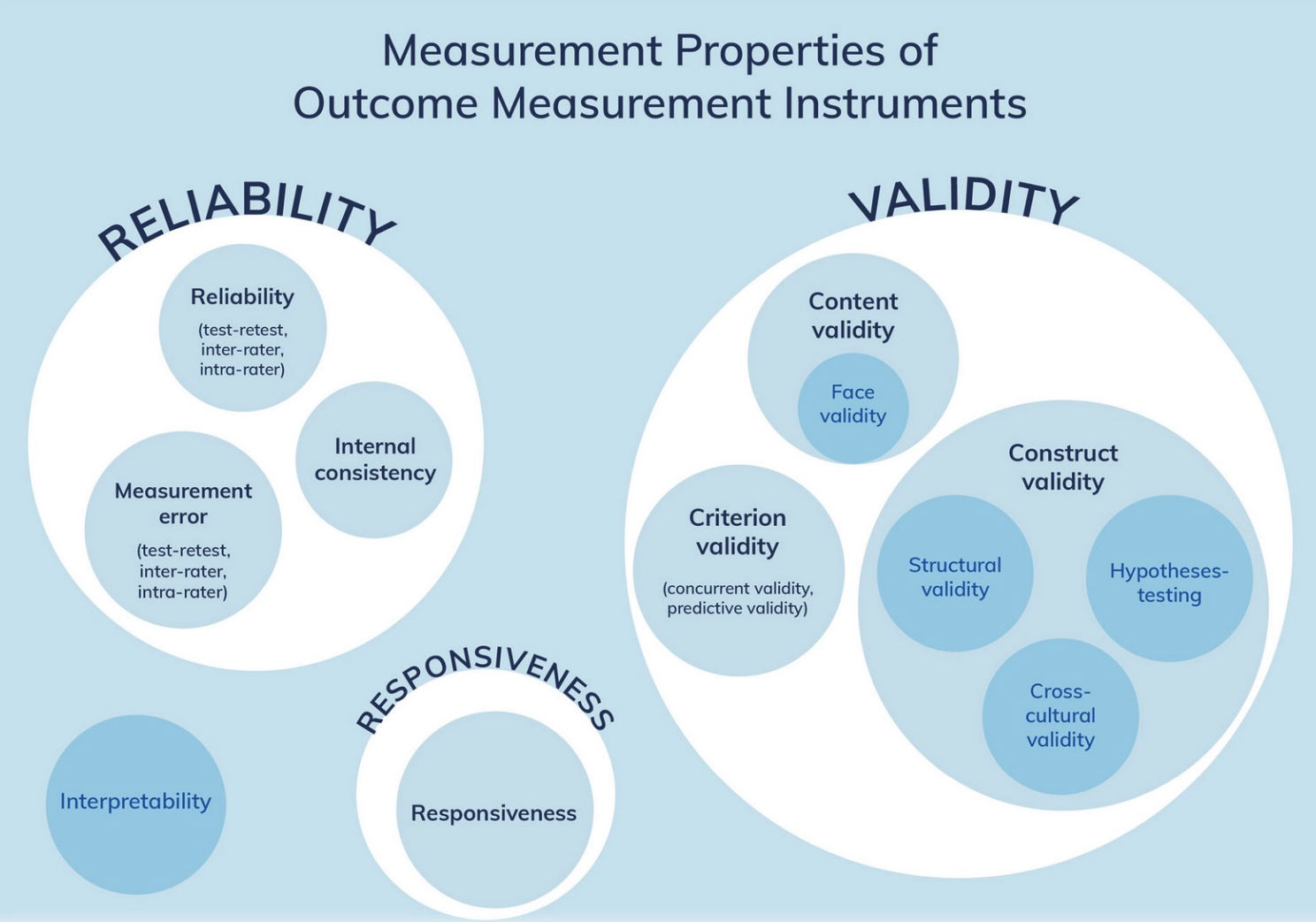
Die Gütekriterien bauen aufeinander auf: Nur ein Assessment, das reliabel ist, kann auch responsiv und valide sein.

14.4.1 Reliabilität
In der klinischen Praxis (und Forschung) ist die Reliabilität von Assessments – also die Zuverlässigkeit – eine Grundvoraussetzung für jede Messung. Sie beschreibt, inwieweit eine Messung frei von Messfehlern ist und zuverlässige Ergebnisse liefert (Mokkink et al. 2010). Ihre Bedeutung wird häufig erst dann deutlich, wenn Messungen wiederholt durchgeführt werden. Ein Beispiel: Physiotherapeut:innen müssen wissen, ob ihre Kolleg:innen ein Video einer Ganganalyse genauso interpretieren wie sie selbst (Inter-Rater-Reliabilität) oder ob sie bei einer erneuten Bewertung des gleichen Videos zu einem späteren Zeitpunkt dieselbe Einschätzung abgeben würden (Intra-Rater-Reliabilität). Im gleichen Sinne ist es entscheidend, ob zwei Therapeut:innen bei der Messung des Bewegungsausmasses einer Schulter zu gleichen Ergebnissen kommen. Unterschiedliche Messungen können jedoch durch verschiedene Faktoren variieren, etwa durch das Messinstrument, durch unterschiedliche Anweisungen der Therapeut:innen oder durch die Verfassung der Patient:innen.
Diese potenziellen Unterschiede – sei es durch das Messinstrument, durch die durchführenden Therapeut:innen, durch die Testperson oder durch die Testbedingungen – beeinflussen die Zuverlässigkeit einer Messung. Die Reliabilität muss deshalb in der Physiotherapie genau überprüft und gewährleistet werden, um aussagekräftige und vergleichbare Ergebnisse zu erzielen.
Zusätzlich zur allgemeinen Definition von Reliabilität als „das Ausmass, in dem eine Messung frei von Messfehlern ist“ gibt es eine erweiterte Definition. Diese beschreibt Reliabilität als „das Ausmass, in dem die Ergebnisse für Patient:innen, deren Zustand sich nicht verändert hat, bei wiederholten Messungen unter verschiedenen Bedingungen gleichbleibend sind“ (Mokkink et al. 2010). Dabei umfasst die Reliabilität die Übereinstimmung der Ergebnisse unter den folgenden Bedingungen:
Arten von Reliabilität (siehe Abbildung 7.4)
- Test-Retest Reliabilität: Stabilität der Ergebnisse über einen bestimmten Zeitraum hinweg.
- Inter-Rater Reliabilität: Übereinstimmung der Ergebnisse, wenn verschiedene Personen die gleiche Messung durchführen.
- Intra-Rater Reliabilität: Konsistenz der Ergebnisse, wenn dieselbe Person die Messung zu verschiedenen Zeitpunkten wiederholt.
- Messfehler: Die durchschnittliche Abweichung einzelner Messungen, wenn das zu messende Objekt unverändert bleibt.
Es gibt noch die interne Konsistenz (Abbildung 14.4), welche die Übereinstimmung der Ergebnisse bei Verwendung unterschiedlicher Item-Sets desselben multi-Item Messinstruments beschreibt. Sie ist relevant bei Fragebögen und wird nicht weiter behandelt in diesem Modul.
14.4.1.1 Reliabilität bei Assessments mit einem quantitativen Messresultat
Wir haben oben das Beispiel mit der Beweglichkeitsmessung des Schultergelenks eingeführt und werden dieses für die folgenden Ausführungen beibehalten. Dieses Beispiel basiert auf einer Reliabilitätsstudie, welche mit 155 Patienten mit Schulterbeschwerden durchgeführt wurde (de Winter et al. 2004). Zwei erfahrene Physiotherapeut:innen (PT1 und PT2) , massen unabhängig voneinander das Bewegungsausmass der passiven Glenohumeral-Abduktion des Schultergelenks mit einem elektronischen Inclinometer. Beide Physiotherapeut:innen massen die Schulter jeder Person zweimal. Zwischen der ersten und der zweiten Messung lag 1 Tag. Die Reihenfolge der Messungen erfolgte randomisiert und verblindet. Ich habe die Daten aus didaktischen Gründen etwas angepasst. Hier sehen Sie die Daten für die Inter-Rater Reliabilität:
Was sehen wir im Punktediagrammen in Abbildung 14.6? Betrachten wir zunächst nur die oberste Abbildung. Sie können mit der Maus über den Plot fahren, um mehr Informationen zu den Daten zu bekommen.
Die Messwerte der Patien:innen variieren
Der kleinste Messwerte ist \(y_{min} = 10°\), der grösste Messwert ist \(y_{max} = 102°\). Wir haben also eine Variabilität zwischen den Patient:innen.
Die Messwerte der Physiotherapeut:innen variieren
Man sieht zwar einen gewissen Zusammenhang der Messwerte zwischen den beiden PT’s, aber der Zusammenhang ist nicht perfekt. Bei einem perfekten Zusammenhang würden alle Punkte exakt auf der Diagonale liegen. Je weiter weg die Punkte von dieser Diagonale liegen, desto schwächer ist der Zusammenhang der Messwerte der beiden PT’s.
Es gibt einen systematischen Fehler
Wenn Sie die oberste Abbildung genau anschauen sehen Sie, dass PT1 durchschnittlich tiefere Werte misst. Wenn man für jede gemessene Person die Differenz zwischen den beiden PT’s berechnet und davon den Mittelwert rechnet, finden wir einen systematischen Fehler von ca 6°.
Quantifizierung der Reliabilität
Würden wir nur ein Mass für den Zusammenhang der Messwerte von PT1 und PT2 berechnen (das wäre der sogenannte Pearson Korrelationskoeffizient \(\rho\)), dann ist das kein gutes Mass für die Reliabiltiät, weil der systematische Fehler nicht berücksichtigt wird. Der Koeffizient, welcher den Zusammenhang von Messwerten von zwei (oder mehr) PT’s unter Berücksichtigung eins systematischen Fehlers quantifiziert, nennt sich Intra-Klassen-Korrelationskoeffizient (engl. Intraclass-correaltion coefficient), kurz ICC. Ein ICC ist ein Mass für die relative Reliabilität und liegt zwischen 0 und 1, also \(ICC \in [0; 1]\), Grundsätzlich gilt, je näher bei 0 desto schlechter und je näher bei 1 desto besser die Reliabilität. Sie können diesen Koeffizienten wie folgt interpretieren:
| ICC-Wert | Interpretation |
|---|---|
| < 0.5 | Schlechte Reliabilität: Die Messungen sind sehr schlecht konsistent, mit wenig Übereinstimmung zwischen den Ratern oder über die Messwiederholungen hinweg. |
| 0.5 - 0.74 | Mässige Reliabilität: Die Messungen zeigen ein mässiges Mass an Konsistenz, jedoch treten noch Unterschiede auf. |
| 0.75 - 0.90 | Gute Reliabilität: Es gibt eine hohe Konsistenz mit minimalen Unterschieden zwischen den Ratern oder wiederholten Messungen. |
| > 0.9 | Exzellente Reliabilität: Die Messungen sind sehr konsistent und zeigen eine starke Übereinstimmung zwischen den Ratern oder über wiederholte Tests hinweg. |
Die Faustregeln aus Tabelle 14.2 gelten sowohl für die Intra- wie die Inter-Rater Reliabilität.
Der berechnete ICC für die Inter-Rater Reliabilität (oberstes Punktediagramm in Abbildung 7.6) beträgt 0.77. Es liegt also eine gute Reliabilität vor.
In Abbildung 14.7 sehen wir, dass die Daten zwischen den Messzeitpunkten etwas weniger variieren als bei der Inter-Rater Reliabilität. Das ist ein typisches und gut nachvollziehbares Phänomen. Der ICC für PT1 beträgt 0.93. Es liegt also eine exzellente Reliabilität vor.
Für PT2 (Abbildung 14.8) ist der ICC nur bei 0.81. Warum? Es liegt ein systematischer Fehler vor, welcher beim ICC entsprechend berücksichtigt wird.
Zur Übersicht noch einmal drei Streudiagramme welche die ICC’s 0.2, 0.5 und 0.8 zeigen. Welcher Plot gehört zu welchem ICC?
Messfehler von Assessments
Der ICC ist ein Mass für die relative Relibilität. Insbesondere in der klinischen Praxis und im Speziellen bei Test-Retests interessieren wir uns für die absolute Reliabilität, den Messfehler von Assessments, (engl. Standard Error of Measuremente, SEM). Würden wir eine sich nicht verändernde Person unendlich mal messen und die Variation (Standardabweichung \(\sigma\)) dieser Messwerte bestimmen, wäre das der SEM. Nun ist es aber kaum möglich, eine Person so oft zu Messen. Viel realistischer ist es, dass wir verschiedene Personen messen. Deshalb gewinnen wir den SEM aus Variabilität zwischen den Personen (dieses \(\sigma\)) und der relativen Reliabilität, dem ICC:
\[ SEM = \sigma_Y \sqrt{1-ICC}, \]
wobei \(\sigma_Y\) die Variabilität zwischen den Messertwen \(Y\) ist.
Die Formel zeigt, dass der SEM bei einer perfekten relativen Reliabilität 0 ist, was bei physiotherapeutischen Assessments nie der Fall ist.
Beim Beispiel mit der Schulterabduktion beträgt der SEM etwa 7.4°.
Wenn Sie nun eine Therapie evaluieren, z. B. wenn Sie die Beweglichkeit der Schulter behandeln und vorher und nach der Behandlung die Beweglichkeit messen, dann wollen Sie wissen, ob eine Veränderung der gemessenen Beweglichkeit eine wahre Veränderung ist oder ob es sich auch um Messfehler handeln könnte. Damit Sie das beurteilen können, müssen Sie wissen, welches die kleinstmögliche Veränderung ist, welche Sie mit dem Assessment messen können. Im englischen bezeichnet man diese Grösse als Smallest Detectable Change oder Minimal detectable Change, MDC.
MDC
Der MDC beschreibt die kleinste messbare Veränderung eines Assessments. Das Wissen über den MDC ist insbesondere bei Test-Retests von zentraler Bedeutung.
Der MDC berechnet sich aus dem SEM:
\[ MDC = SEM * 1.96 * \sqrt{2}. \]
Bei unserem Beispiel beträgt der MDC 20.5°. Wenn Sie also z. B. eine Veränderung von 15° messen, wissen Sie nicht, ob dieser Unterschied auf Messfehler oder die Behandlung zurückzuführen ist. Bei einer Veränderung von 30° können Sie hingegen davon ausgehen, dass es sich nicht nur um Messfehler handelt.
Tip
Möchten Sie ein konkretes Beispiel? Dann kann ich Ihnen die Studie von Deiss et al. (2024) wärmstens empfehlen.
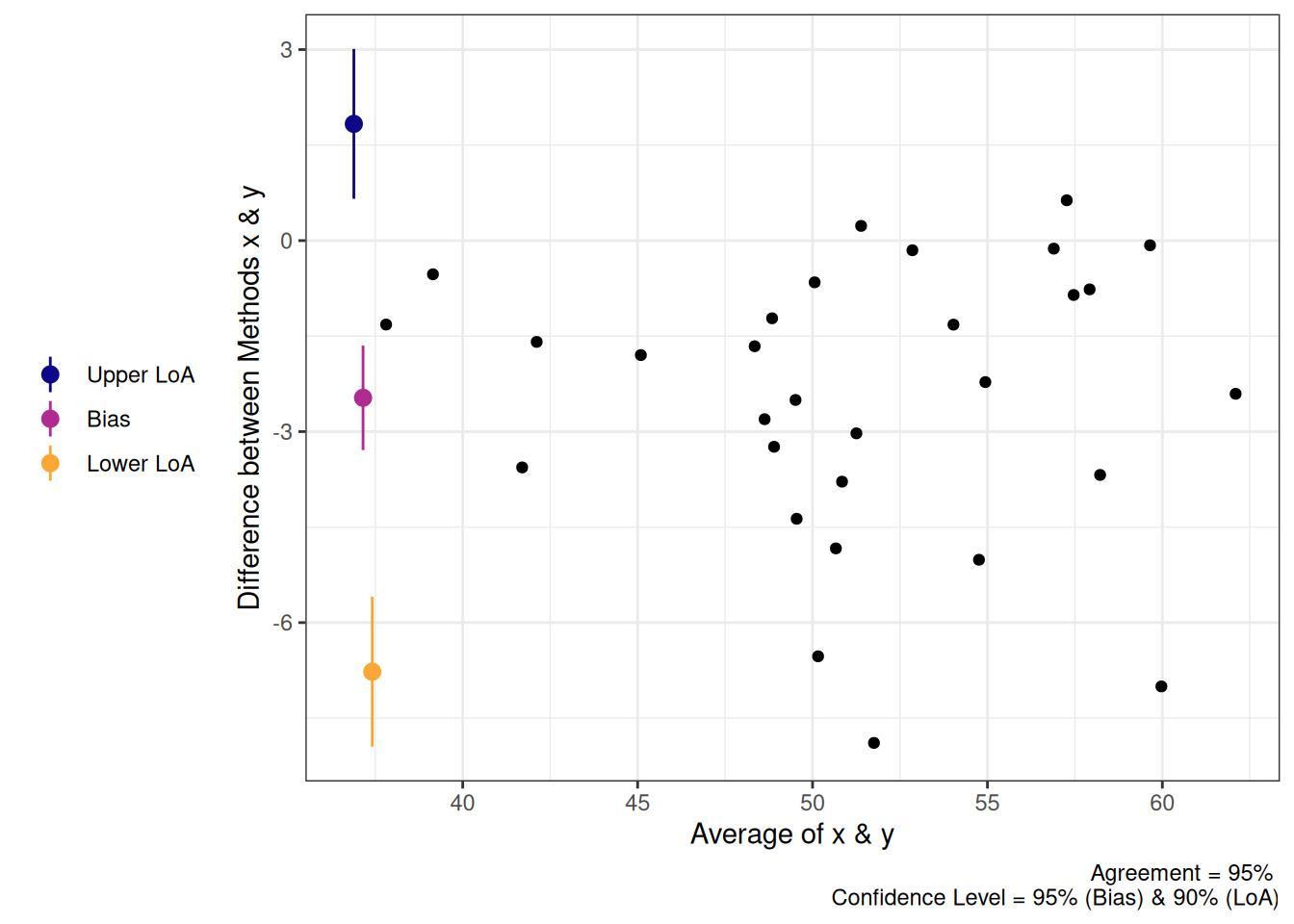
14.4.1.2 Bland-Altman Plot
Es gibt noch eine weitere Möglichkeit, die absolute Reliabilität grafisch darzustellen: mit einem Bland-Altman Plot (Abbildung 14.10). Dieser visualisiert die Differenzen zwischen zwei Ratern oder Messzeitpunkten gegen deren Mittelwert. Die mittlere Differenz (violett) ist der Bias, also der systematische Fehler, was - wie wir jetzt wissen - nicht das gleiche ist wie der SEM!) Die so genannten Limits of Agreement (LoA, blau, resp. orange) geben den Bereich an, in dem z.B. 95% der Differenzen liegen:
\[\text{Bias} \pm z \times SD_{\text{Differenzen}}.\] Bei einem Level of Agreement von 95% ist der z-Wert 1.96.
Wenn man also zwei Messungen vergleicht, kann man mit 95% Sicherheit erwarten, dass ihre Differenz im LoA-Bereich liegt. Zusätzlich werden für den Bias und die LoA noch Konfidenzintervalle dargestellt (senkrechte Striche). Ein proportionaler Bias liegt vor, wenn die gedachte Regressionslinie eine Steigung \(\ne 0\) hat.
14.4.1.3 Reliabilität bei Assessments mit einem qualitativen Messresultat
Viele physiotherapeutische Assessments resultieren nicht in einem numerischen Resultat. Ein typischen Beispiel sind klinische Tests, bei welchen das Resultat positiv oder negativ ist. Wir verwenden als Beispiel eine eigene Studie, in der die Reliabilität des FADDIR-Tests untersucht wurde (Lutz et al. 2021). Mit diesem Test soll beurteilt werden, ob ein femoroacetabuläres Impingement vorliegt oder nicht.
In der folgenden Tabelle sind die Resultate zusammengefasst:
| Rater2: negativ | Rater2: positiv | Sum | |
|---|---|---|---|
| Rater1: negativ | 6 | 5 | 11 |
| Rater1: positiv | 10 | 38 | 48 |
| Sum | 16 | 43 | 59 |
6 Mal haben beide Rater ein negatives Resultat erhalten, 38 Mal beide ein positives. In 10 Fällen hat Rater 1 ein positives und Rater 2 ein negatives Resultat erhalten. Umgekehrt hat 5 Mal Rater 1 ein negatives und Rater 2 ein positives Resultat erhalten.
Wir könnten also sagen, dass die Übereinstimmung der Rater \(\frac{44}{59}=0.75\), also 75% beträgt. Diese Aussage ist zwar nicht falsch, im Kontext der Reliabilität aber irreführend. Angenommen ein positives und negatives Resultat ist gleich wahrscheinlich, würde man alleine durch Zufall eine Übereinstimmung von 50% erwarten!
Wir benötigen also eine Statistik, welche die Übereinstimmung der Rater unter Berücksichtigung der durch Zufall zu erwartenden Übereinstimmung quantifiziert. Diese Statistik heisst Kappa (\(\kappa\)). Kappa ist eine Zahl im Intervall [-1; 1]. 1 bedeutet “perfekte” Reliabilität, 0 bedeutet eine Übereinstimmung, welche genau der zufälligen Übereinstimmung entspricht. Negative Kappa-Werte würden bedeuten, dass die Übereinstimmung der Rater schlechter ist als jene, welche man alleine durch Zufall erwarten würde (ein Münzwurf wäre besser).
In unserem Beispiel beträgt das Kappa 0.29. Auch hier gilt: je näher der Wert bei 1 ist, desto besser ist die Reliabilität. Sie können \(\kappa\) wie folgt interpretieren:
| Kappa-Wert | Interpretation |
|---|---|
| ≤ 0 | Keine Übereinstimmung |
| 0.01 bis 0.20 | Keine bis leichte Übereinstimmung |
| 0.21 bis 0.40 | Mässige Übereinstimmung |
| 0.41 bis 0.60 | Moderate Übereinstimmung |
| 0.61 bis 0.80 | Substantielle Übereinstimmung |
| ≥ 0.8 | Nahezu perfekte Übereinstimmung |
Der Kappa-Koeffizient bezeichnet die relative Reliabilität. Er kann sowohl für die Intra- wie die Inter-Rater Reliabilität verwendet werden. Ein Mass für die absolute Reliabilität wie den MDC gibt es für Assessments mit qualitativen Resultaten nicht.
14.4.2 Responsivität
Die Responsivität eines Assessments ist entscheidend, um klinisch relevante Veränderungen über die Zeit hinweg genau erfassen zu können. Ein Synonym für Responsivität ist Änderungssensitivität. Es gibt verschiedene Methoden, um die Responsivität zu evaluieren. Wir konzentrieren uns auf ein Konzept, welches insbesondere für die Klinik relevant ist. Zwei wichtige Begriffe in diesem Zusammenhang sind der MDC aus dem letzten Kapitel und die Minimal Clinically Important Difference” (MCID). Die MCID ist keine Eigenschaft des Assessments selbst, sondern wird in speziell dafür konzipierten Studien ermittelt. Sie beschreibt die minimale Veränderung, welche beim Resultat eines Assessments erreicht werden muss, damit diese für Patient:innen klinisch relevant ist. Also eine Verbesserung oder Verschlechterung, die im Alltag spürbar ist. Während der MDC auf die Messgenauigkeit fokussiert, ist die MCID ein Mass dafür, ob die Veränderung auch eine Bedeutung für Patient:innen hat. Auch wenn wir beispielsweise die Knieflexion auf das Grad genau messen könnten, wäre 1° Verbesserung wohl kaum relevant für Patient:innen.
Important
Ein Assessment ist dann responsiv, wenn MDC < MCID.
14.4.2.1 Beispiele:
Eine Studie hat den SEM und die MCID der Short Physical Performance Battery (SPPB) evaluiert (Perera et al. 2006). Die SPPB ist ein Assessment zu Beurteilung der Balance, Kraft der unteren Extremität und der funktionellen Kapazität bei älteren Menschen. Das Assessment resultiert in einem Score zwischen 0 und 12 Punkten. Der SEM beträgt 1.42 Punkte. Mit der Formel oben erhalten wir einen MDC von \(1.42 \times 1.96 \times \sqrt{2}= 3.9\) Punkten. Die MCID wird in der Studie mit 1.34 Punkten angegeben. Laut dieser Studie ist also der MDC >> MCID, was bedeutet, dass wir klinisch relevante Veränderungen nicht zuverlässig messen können. Das Assessment ist also zumindest bei der untersuchten Population nicht responsiv.
Der MDC der VAS (von 0 bis 100) bei Personen nach einem Einsatz einer totalen Knieprothese beträgt 16.1. Die MCID für eine Schmerzverbesserung beträgt 22.6 und für eine Schmerzverschlechterung 29.1 (Danoff et al. 2018). Die VAS ist demnach responsiv, d.h. wir können eine klinisch relevante Zu- oder Abnahme des Schmerzes zuverlässig erfassen.
14.4.3 Validität
Validität bei Assessments beschreibt die Gültigkeit eines Messinstruments – also die Fähigkeit eines Tests oder Verfahrens, tatsächlich das zu messen, was es vorgibt zu messen. Im Kontext der Diagnostik, Forschung und Therapie bedeutet Validität daher, dass ein Instrument oder Verfahren relevante und sinnvolle Ergebnisse liefert, die für den jeweiligen Zweck – wie die Beurteilung von Fähigkeiten, Symptomen oder Risiken – nützlich sind.
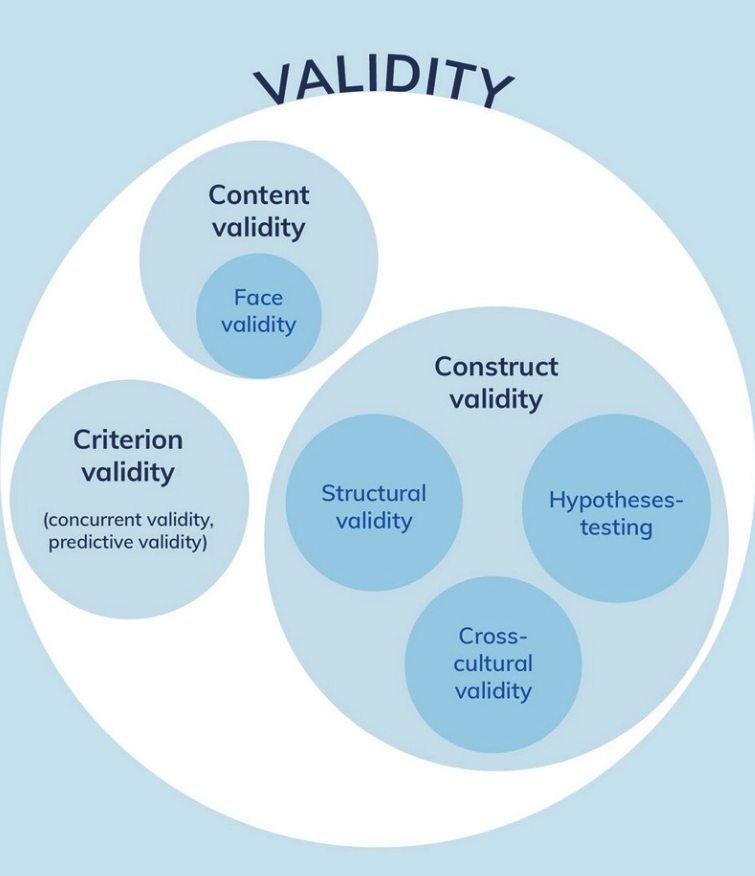
Im Kontext von Assessments beschreibt Cosmin verschiedene Arten der Validität (Abbildung 14.11). In der Folge werden die verschiedenen Validitätstypen kurz erläutert, wir werden aber in diesem Modul nur die Kriteriumsvalidität genauer anschauen.
Inhaltsvaldität (engl. Content Validity)
Dieser Validitätstyp ist insbesondere dann relevant, wenn Konstrukte wie z. B. die QoL oder die Balance gemessen werden sollen.
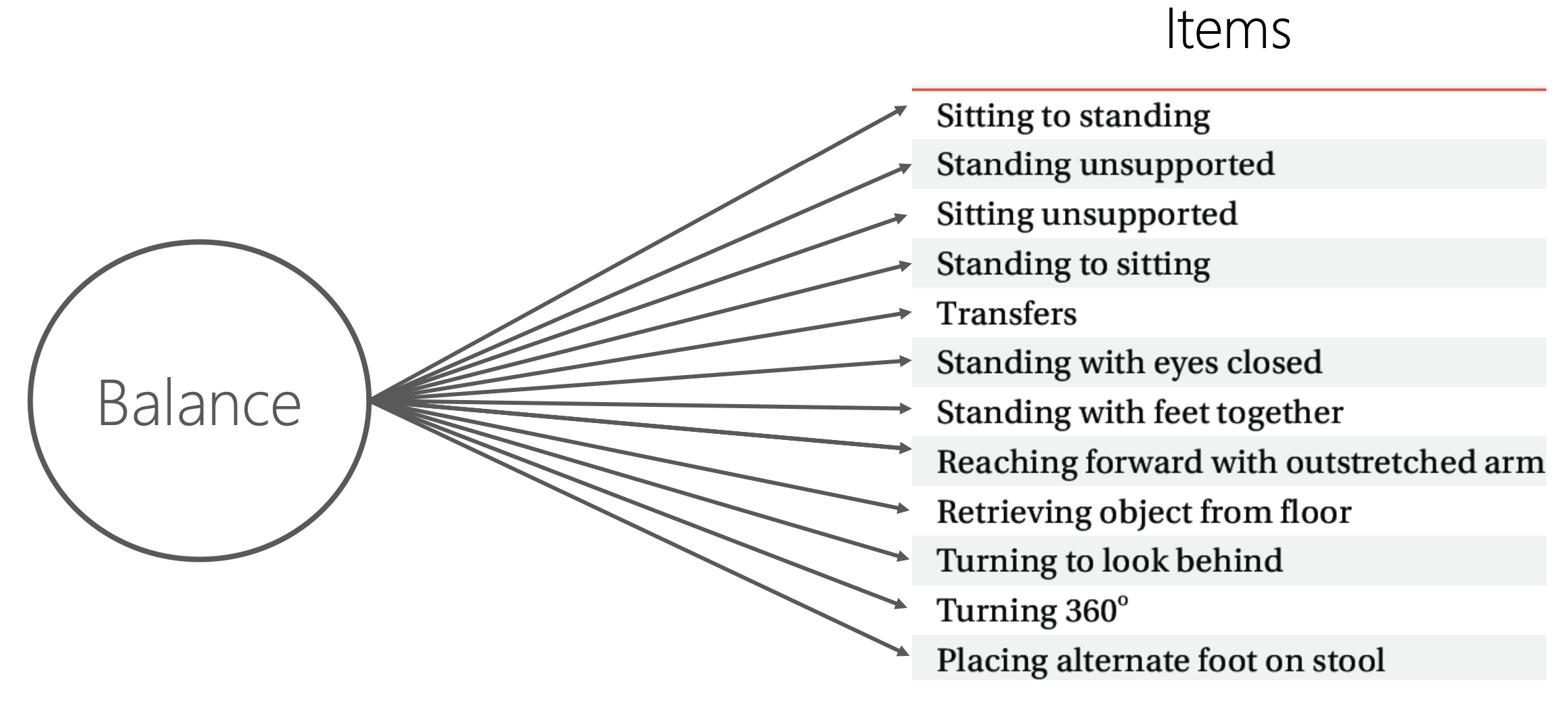
Inhaltsvalidität bezieht sich darauf, inwieweit ein Instrument alle relevanten Aspekte des zu messenden Konstrukts abdeckt. Die Inhalte des Assessments, also die Items in Abbildung 14.12, sollten genau die Eigenschaften widerspiegeln, die im Zusammenhang mit dem Konstrukt (hier Balance) wichtig sind. Inhaltsvalidität wird oft durch Expertenurteile und Konsensverfahren beurteilt. Ein physiotherapeutisches Assessment hat eine hohe Inhaltsvalidität, wenn die enthaltenen Items die gesamte Bandbreite des zu messenden Konstrukts von Patient:innen abdecken.
Eine Unterkategorie der Inhaltsvalidität ist die Augenscheinvalidität (engl. Face Validity). Augenscheinvalidität bezieht sich darauf, ob das Instrument auf den ersten Blick plausibel und geeignet erscheint, das gewünschte Konstrukt oder Merkmal zu messen. Augenscheinvalidität erfolgt häufig durch Rückmeldungen von Expert:innen und Patient:innen. Augenscheinvalidität ist oft der erste Schritt einer Validierung.
Konstruktvalidität (engl. Construct Validity)
Konstruktvalidität zeigt an, ob das Instrument tatsächlich das Konzept oder Konstrukt misst, das es zu messen vorgibt. Dabei wird geprüft, ob das Instrument mit anderen Messungen zusammenhängt, die dasselbe oder ein verwandtes Konstrukt messen. Konstruktvalidität kann durch Hypothesentests (wie erwartete Korrelationen mit anderen Instrumenten) überprüft werden. Wenn wir beispielsweise aus dem in Abbildung 14.12 gezeigten Balance-Assessment einen Score bilden, würden wir erwarten, dass dieser mit dem Resultat eines anderen Assessments zur Beurteilung der Balance korreliert.
Konvergente Validität ist eine Unterkategorie der Konstruktvalidität. Sie misst, ob das Instrument mit anderen Instrumenten, die das gleiche oder ein ähnliches Konzept messen, korreliert. Die diskriminante Validität hingegen prüft, ob das Instrument nur schwach oder gar nicht mit Instrumenten korreliert, die andere Konzepte messen.
Eine weitere Unterkategorie der Konstruktvalidität ist die kreuzkulturelle Validität. Sie bezieht sich darauf, ob die Ergebnisse des Instruments für verschiedene kulturelle oder sprachliche Gruppen gültig sind und auf dieselbe Weise interpretiert werden können. Diese Art der Validierung ist insbesondere dann wichtig, wenn Fragebögen in eine andere Sprache übersetzt werden.
Kriteriumsvalidität (engl. Criterion Validity)
Kriteriumsvalidität wird oft als höchste Validitätsstufe beschrieben. Sie beschreibt, in welchem Mass die Ergebnisse des Instruments mit einem externen “Goldstandard” oder einem anderen objektiven Referenzstandard übereinstimmen. Der Goldstandard wird etwas überspitzt formuliert als “Wahrheit” angesehen, man vergleicht also quasi die Messresultate mit der “Wahrheit”. Die Kriteriumsvalidität wird in zwei Unterkategorien unterteilt:
- Übereinstimmende Validität (engl. Concurrent Validity): Zeigt die Übereinstimmung der Ergebnisse eines Instruments mit denen eines anderen Instruments (Goldstandard), das gleichzeitig durchgeführt wird.
- Prognostische Validität (engl. Predictive Validity): Zeigt, inwiefern die Ergebnisse eines Instruments zukünftige Ereignisse oder Zustände vorhersagen können. Ein physiotherapeutisches Assessment, das beispielsweise die Sturzrisiko-Vorhersage misst, sollte eine hohe prognostische Validität haben, wenn es zuverlässige Vorhersagen über zukünftige Stürze treffen kann.
14.4.3.1 Kriteriumsvalidtät bei diagnostischen Tests
Sie alle führen während der körperlichen Untersuchung von Patient:innen klinische Tests durch. Kommt beispielsweise ein Patient mit Schmerzen im Lendenbereich zu Ihnen in die Therapie, führen Sie ggf. einen Test des Iliosakralgelenks durch. Solche diagnostischen Tests haben zwei mögliche Outcomes: der Test ist positiv oder negativ. Der Test ist dann valide, wenn er das misst, was er messen soll. In diesem Beispiel also, ob das Ilioskralgelenk betroffen ist oder nicht.
Vier zentrale Aspekte der Kriteriumsvalidität diagnostischer Tests interessieren uns ganz besonders:
- Mit welcher Wahrscheinlichkeit ist ein Test positiv, wenn die Pathologie in Wahrheit vorliegt?
- Mit welcher Wahrscheinlichkeit ist ein Test negativ, wenn die Pathologie in Wahrheit nicht vorliegt?
- Mit welcher Wahrscheinlichkeit liegt eine Pathologie vor, wenn der Test positiv ausfällt?
- Mit welcher Wahrscheinlichkeit liegt eine Pathologie nicht vor, wenn der Test negativ ausfällt?
Aufmerksame Leser:innen stellen fest, dass es sich bei den oben formulierten Wahrscheinlichkeiten um bedingte Wahrscheinlichkeiten handelt. Dieses Kapitel hat zum Ziel, dass Sie diese bedingten Wahrscheinlichkeiten berechnen und korrekt interpretieren können.
Motivationsbeispiel
Stellen Sie sich vor, Sie erwarten ein Kind und machen im Rahmen der pränatalen Untersuchung einen Test bzgl. Trisomie 21. Stellen Sie sich vor, der Test ist positiv. Welche Frage liegt Ihnen auf der Zunge? Genau: Sie wollen wissen, mit welcher Wahrscheinlichkeit ihr Kind nun tatsächlich Trisomie 21 hat (3. Frage oben).
Genau diese Frage hat man im Rahmen einer Studie (Bramwell, West, and Salmon 2006) gestellt an:
- 43 schwangere Frauen
- 40 Begleiter:innen der schwangeren Frauen
- 42 Hebammen
- 41 Frauenärzt:innen
Zudem hat man folgende Informationen angegeben:
- Wahrscheinlichkeit, dass der Test positiv ist, wenn die Pathologie in Wahrheit vorliegt: 90%
- Wahrscheinlichkeit, dass der Test negativ ist, wenn die Pathologie in Wahrheit nicht vorliegt: 99%
- Relative Häufigkeit der Krankheit bei ungeborenen Kindern: 1%
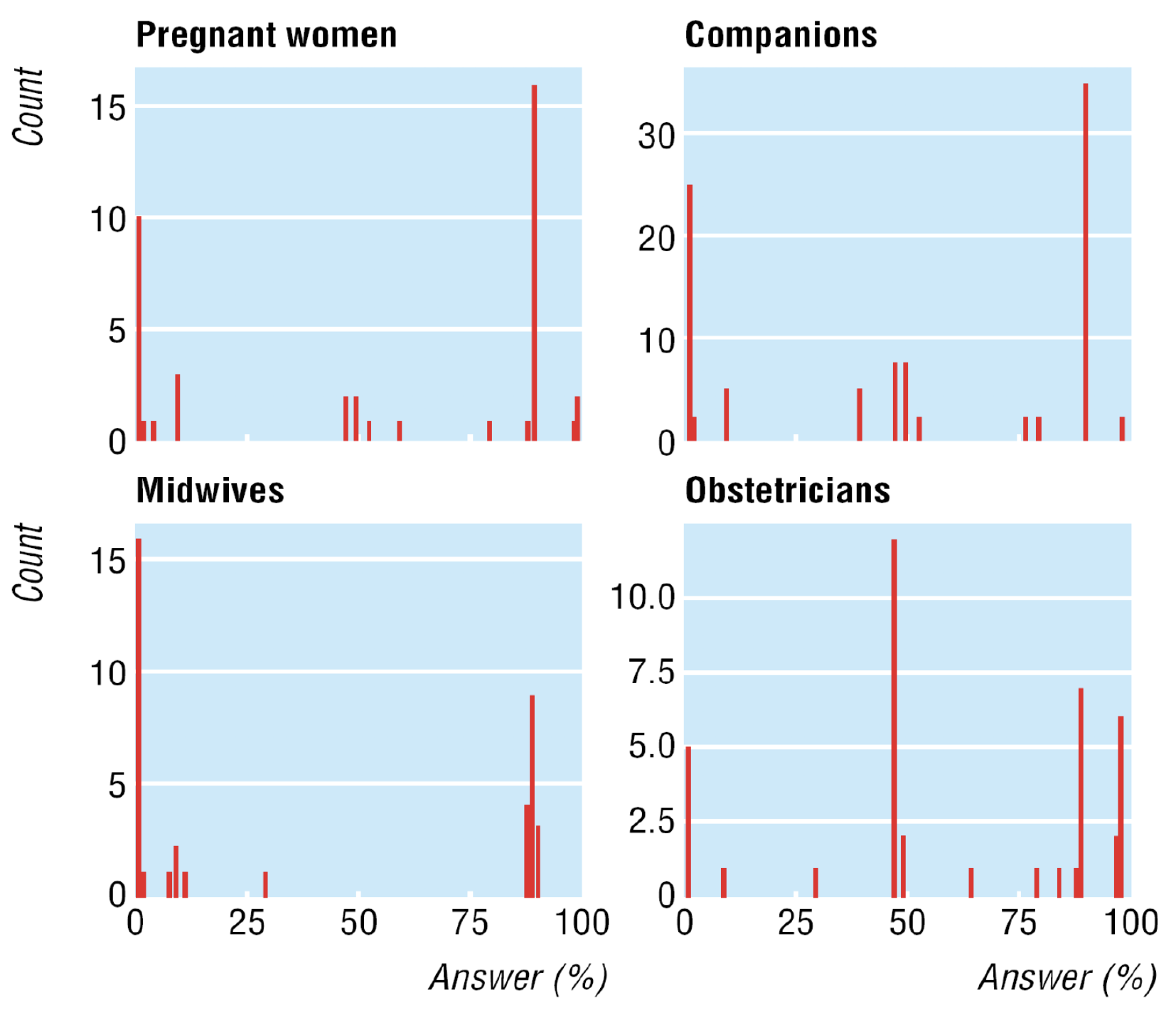
Die Abbildung Abbildung 14.13 zeigt, dass bei allen befragten Gruppen, die Wahrscheinlichkeit für die Frage Was ist die Wahrscheinlichkeit, dass das Baby das Down-Syndrom hat? stark variieren. Die Angegebenen Wahrscheinlichkeiten reichen von 0 bis 100% - eine maximal grosse Diskrepanz. Es könnte also sein, dass der eine Frauenarzt sagt, die Wahrscheinlichkeit ist 99%, während ein anderer sagt, sie ist 1% - nicht sehr vertrauenswürdig.
Ich hoffe dieses Beispiel zeigt Ihnen auf, dass es wichtig ist, sich mit bedingten Wahrscheinlichkeiten zu beschäftigen. Kann man nämlich die oben gestellte Frage nicht beantworten, ist der Einsatz von diagnostischen Tests im besten Fall ein schöner Zeitvertrieb.
Beispiel: Der vordere Schubladentest
Wir verwenden im Folgenden ein physiotherapeutisches Beispiel, um wichtige Begriffe und Konzepte zu erläutern. Der vordere Schubladen-Test (engl. anterior drawer Test) ist ein diagnostischer Test, welcher durchgeführt wird, um zu beurteilen, ob das vordere Kreuzband (VKB) intakt ist oder nicht. Das Beispiel und die verwendeten Werte basieren auf einer Metaanylse (Sokal et al. 2022). Um die Kriteriumsvalidität zu beurteilen, müssen die Resultate des Tests mit einem Goldstandard verglichen werden. Wir verwenden hier die Magnetresonanztomographie als Goldstandard.
Wie bei der Reliabilität von kategorialen Merkmalen kann man auch die Resultate für die Kriteriumsvalidität in einer Kreuztabelle darstellen:
| VKB = ruptur | VKB = intakt | Sum | |
|---|---|---|---|
| Test = pos | 104 | 56 | 160 |
| Test = neg | 21 | 319 | 340 |
| Sum | 125 | 375 | 500 |
Wir sehen in Tabelle 14.5, dass 500 Personen untersucht wurden und von diesen ein Viertel eine VKB-Ruptur aufweist. Tatsächlich schätzt man, dass ca. 25% der Knieverletzungen das VKB betreffen. Dieser Anteil wird als Prävalenz dieser Stichprobe bezeichnet. Im Allgemeinen beschreibt die Prävalenz den Anteil einer Bevölkerung oder einer Bevölkerungsgruppe, der zu einem bestimmten Zeitpunkt von einer Krankheit betroffen ist. Die Prävalenz wird in der Regel als Prozentsatz, oder als Häufigkeit pro 1’000 oder pro 100’000 Personen angegeben. Die hier genannte Prävalenz von 25 % lässt sich in diesem Fall nicht auf die gesamte Bevölkerung übertragen, weil kaum jede vierte Person eine VKB-Ruptur hat. Sie bezieht sich daher auf eine eingegrenzte Gruppe, z. B. Menschen, die sich am Knie verletzt haben. Hätten wir keinen klinischen Test zur Verfügung, würden wir die Wahrscheinlichkeit für eine VKB-Ruptur bei dieser Gruppe auf 25% schätzen. Daher nennt man diese Grösse auch Prä-Test-Wahrscheinlichkeit.
Weiter sehen wir in Tabelle 14.5, dass 104 Personen richtigerweise als “positiv” beurteilt wurden. Es gibt demnach 104 richtig-positive (engl. true positives, TP) Beurteilungen. Im gleichen Sinne gibt es 21 falsch-negative Beurteilungen (engl. false negative, FN), 56 falsch-positive Beurteilungen (engl. false positive, FP) und 319 richtig-negative Beurteilungen (engl, true negative, TN).
Widmen wir uns nun den Wahrscheinlichkeiten, genauer den bedingten Wahrscheinlichkeiten im Zusammenhang mit diesem Beispiel. Dazu führen wir zunächst folgende Notation ein:
- \(Pr(T)\) ist die Wahrscheinlichkeit, dass Ereignis \(T\) eintrifft. In unserem Beispiel notieren wir einen positiven Test mit \(T\)
- Das Ereignis \(T^C\) ist das Komplement von \(T\), also dass ein Test negativ ist. Somit gilt \(Pr(T^C) = 1 - Pr(T)\).
- \(Pr(R)\) ist die Wahrscheinlichkeit, dass Ereignis \(R\) eintrifft. In unserem Beispiel notieren wir das Vorhandensein einer VKB-Ruptur mit \(R\). \(Pr(R)\) entspricht somit der Prävalenz.
- Das Ereignis \(R^C\) ist das Komplement von \(R\), also dass keine VKB-Ruptur vorliegt. Somit gilt \(Pr(R^C) = 1 - Pr(R)\).
- \(Pr(T \cap R)\) ist die gemeinsame Wahrscheinlichkeit von \(T\) und \(R\), also ein positiver Tests und das Vorhanden sein einer VKB-Ruptur. Achtung: weil das Testresultat nicht unabhängig ist vom VKB-Status, ist \(Pr(T \cap R) \ne Pr(T) Pr(R)\) (die Multiplikationsregel von Wahrscheinlichkeiten gilt nur unter Unabhängigkeit).
- \(Pr(T | R)\) ist die Wahrscheinlichkeit für \(T\), gegeben \(R\) ist eingetroffen. Also bei unserem Beispiel, die Wahrscheinlichkeit dafür, dass der Test positiv ist, gegeben eine VKB-Ruptur liegt vor.
- \(Pr(R | T)\) ist die Wahrscheinlichkeit für \(R\), gegeben \(T\) ist eingetroffen. Also bei unserem Beispiel, die Wahrscheinlichkeit dafür, dass eine VKB-Ruptur vorliegt, gegeben der Test ist positiv.
Zu guter Letzt brauchen wir noch Bayes’ Theorem:
\[ Pr(R | T) = \frac{Pr(T|R)Pr(R)}{Pr(T|R)Pr(R) + Pr(T|R^C)Pr(R^C)}. \]
Die Formel sieht kompliziert aus, aber anhand der folgenden Ausführungen werden Sie in der Lage sein, die entsprechenden Werte einzusetzen, um \(Pr(R | T)\) zu berechnen. Zur Erinnerung: \(Pr(R | T)\) ist die Wahrscheinlichkeit, dass eine Ruptur vorhanden ist, gegeben der Test ist positiv. Das ist genau die Frage aus dem Einstiegsbeispiel und somit die entscheidende Frage im klinischen Setting.
Sensitivität
Definition
Die Sensitivität eines Tests bezeichnet seine Fähigkeit, “Kranke” als “krank” zu identifizieren:
\[ Sensitivität = Pr(T|R). \]
Zur besseren Nachvollziehbarkeit schauen wir noch einmal die Kreuztabelle an:
| VKB = ruptur | VKB = intakt | Sum | |
|---|---|---|---|
| Test = pos | 104 | 56 | 160 |
| Test = neg | 21 | 319 | 340 |
| Sum | 125 | 375 | 500 |
Die Wahrscheinlichkeit, dass der Test positiv ausfällt, gegeben es liegt eine VKB-Ruptur vor, beträgt \(\frac{104}{125} = 0.832 = 83.2 \%\). Weil es eine bedingte Wahrscheinlichkeit ist, schauen wir nur die erste Spalte der Tabelle an (\(R\)).
Die Sensitivität des Tests beträgt 83.2%. Der Test identifiziert also 83.2% der Personen mit einer VKB-Ruptur korrekt als solche. Bei 16.8% der Personen mit einer VKB-Ruptur übersieht er diese.
Spezifität
Definition
Die Spezifität eines Tests bezeichnet seine Fähigkeit, “Gesunde” als “gesund” zu identifizieren:
\[ Spezifität = Pr(T^C|R^C). \]
Zur besseren Nachvollziehbarkeit schauen wir noch einmal die Kreuztabelle an:
| VKB = ruptur | VKB = intakt | Sum | |
|---|---|---|---|
| Test = pos | 104 | 56 | 160 |
| Test = neg | 21 | 319 | 340 |
| Sum | 125 | 375 | 500 |
Die Wahrscheinlichkeit, dass der Test negativ ausfällt, gegeben es liegt keine VKB-Ruptur vor, beträgt \(\frac{319}{375} = 0.851 = 85.1 \%\). Weil es eine bedingte Wahrscheinlichkeit ist, schauen wir nur die zweite Spalte der Tabelle an (\(R^C\)).
Die Spezifität des Tests beträgt 85.1%. Der Test identifiziert also 85.1% der Personen ohne VKB-Ruptur korrekt als solche. Bei 14.9% der Personen ohne VKB-Ruptur ist der Test dennoch positiv (FP).
Positiver prädiktiver Wert
Definition
Der positive prädiktive Wert (PPW) eines Tests ist die Wahrscheinlichkeit, dass bei einem positiven Test die “Krankheit” vorliegt:
\[ PPW = Pr(R|T). \]
Zur besseren Nachvollziehbarkeit schauen wir noch einmal die Kreuztabelle an:
| VKB = ruptur | VKB = intakt | Sum | |
|---|---|---|---|
| Test = pos | 104 | 56 | 160 |
| Test = neg | 21 | 319 | 340 |
| Sum | 125 | 375 | 500 |
Die Wahrscheinlichkeit, dass die “Krankheit” vorliegt, gegeben der Test fällt positiv aus, beträgt \(\frac{104}{160} = 0.65 = 65 \%\). Weil es eine bedingte Wahrscheinlichkeit ist, schauen wir nur die erste Zeile der Tabelle an (\(T\)).
Der PPW des Tests beträgt 65%. Die Wahrscheinlichkeit, dass bei einem positiven Test wirklich eine VKB-Ruptur vorliegt, ist 65%.
Negativer prädiktiver Wert
Definition
Der negative prädiktive Wert (NPW) eines Tests ist die Wahrscheinlichkeit, dass bei einem negativen Test die “Krankheit” nicht vorliegt:
\[ NPW = Pr(R^C|T^C). \]
Zur besseren Nachvollziehbarkeit schauen wir noch einmal die Kreuztabelle an:
| VKB = ruptur | VKB = intakt | Sum | |
|---|---|---|---|
| Test = pos | 104 | 56 | 160 |
| Test = neg | 21 | 319 | 340 |
| Sum | 125 | 375 | 500 |
Die Wahrscheinlichkeit, dass die “Krankheit” nicht vorliegt, gegeben der Test fällt negativ aus, beträgt \(\frac{319}{340} = 0.938 = 93.8 \%\). Weil es eine bedingte Wahrscheinlichkeit ist, schauen wir nur die zweite Zeile der Tabelle an (\(T^C\)).
Der NPW des Tests beträgt 93.8%. Die Wahrscheinlichkeit, dass bei einem negativen Test wirklich keine VKB-Ruptur vorliegt, ist 93.8%.
14.4.3.1.1 Prädiktive Werte und Prävalenz
Während die Sensitivität und die Spezifität Eigenschaften des Tests sind, sind der PPW und der PPW eine Funktion der Prävalenz, bzw. der Prä-Test-Wahrscheinlichkeit. Das heisst sowohl der PPW sowie der NPW verändern sich mit steigender oder sinkender Prävalenz, trotz konstanter Sensitivität und Spezifität.
Wenn Sie in Abbildung 14.14 mit der Maus auf die Kurven bei der Stelle \(Pr(R) = 0.25\) gehen, finden Sie die oben berechneten Werte.
Important
- Bei konstanter Sensitivität und Spezifität nimmt der PPW mit zunehmender Prävalenz zu und umgekehrt.
- Bei konstanter Sensitivität und Spezifität nimmt der NPW mit zunehmender Prävalenz ab und umgekehrt.
Nehmen wir nun an, Sie wenden den vorderen Schubladentest bei einer hochrisiko-Gruppe an (Knieverletzung nach Skiunfall). Nehmen wir an, die Prävalenz von VKB-Rupturen in dieser Population beträgt 60% (\(Pr(R) = 0.6\)). Die Sensitivität und Spezifität sind Eigenschaften des Tests und bleiben demnach gleich (\(Pr(T|R) = 0.832\) und \(Pr(T^C|R^C = 0.851\)).
Wie gross ist die Wahrscheinlichkeit, dass eine Person eine VKB-Ruptur hat, gegeben der Test ist positiv (\(Pr(R|T)\))?
Um diese klinisch sehr wichtige Frage zu klären, brauchen wir Bayes’ Thorem:
\[ Pr(R | T) = \frac{Pr(T|R)Pr(R)}{Pr(T|R)Pr(R) + Pr(T|R^C)Pr(R^C)} \]
\[ = \frac{0.832 \times 0.6}{0.832 \times 0.6 + (1-0.851) \times (1-0.6)} \]
\[ = 0.893 = 89.3 \%. \]
Sie können das Resultat erneut in Abbildung 14.14 überprüfen.
Selbstverständlich kommen wir auf die gleiche Art und Weise auch an den NPW für die neue Situation:
\[ Pr(R^C | T^C) = \frac{Pr(T^C | R^C) Pr(R^C)}{Pr(T^C | R^C) Pr(R^C) + Pr(T^C | R) Pr(R)} \]
\[ = \frac{0.851 \times (1-0.6)}{0.851 \times (1-0.6) + (1-0.832) \times 0.6} \]
\[ = 0.772 = 77.2%. \]
Zum Schluss habe ich Ihnen die Berechnungen noch in einer Tabelle visualisiert:
| VKB = ruptur | VKB = intakt | Zeiltentotal | |
|---|---|---|---|
| Test = pos | \(Pr(T|R) Pr(R)\) | \(Pr(T|R^C)Pr(R^C)\) | \(Pr(T)\) |
| Test = neg | \(Pr(T^C | R) Pr(R)\) | \(Pr(T^C | R^C) Pr(R^C)\) | \(Pr(T^C)\) |
| Spaltentotal | \(Pr(R)\) | \(Pr(R^C)\) | 1 |
Der etwas lange Teil im Nenner des Bruchs ist also lediglich die Zeilensumme für \(T\), bzw. \(T^C\).
14.5 Risk-of-Bias Analyse in Diagnostikstudien
Wie Sie für die Bewertung von Interventionsstudien z.B. das Gate-Frame oder die PEDro-Skala kennen, gibt es auch für diagnostische Studien verschiedene Bewertungsinstrumente. Wir empfehlen Ihnen, die Instrumente der Cosmin-Gruppe zu verwenden. Sie finden die Ausführliche Beschreibung des Tools unter diesem Link.
Wir beschränkten uns bei der RoB-Analyse in diesem Modul auf drei Aspekte:
- Reliabilität (Box 6 im Dokument)
- Messfehler (Box 7 im Dokument)
- Kriteriumsvalidität (Box 8 im Dokument)
Wir können das Resultat einer Messung formal darstellen als:
\[ X_i = T_i + E_i \]
wobei \(X_i\) der gemessene Wert der \(i\)-ten Person ist, \(T_i\) der wahre Wert der \(i\)-ten Person und \(E_i\) der Messfehler bei der \(i\)-ten Person.
Anders als in der klassichen Statistik gibt es für \(E\) keine Annahmen bezüglich seiner Verteilung (z. B., dass diese normalverteilt um 0 sind: \(E \sim \mathcal{N}(0, \sigma^2)\)). Der Messfehler kann also auch systematisch von \(0\) abweichen. Kenntnisse über \(E\) sind daher entscheidend, um die Ergebnisse von Assessments korrekt zu interpretieren.
Important
- \(E\) kann klein sein, aber von 0 abweichen → gute Reliabilität aber schlechte Validität
- \(E\) kann gross sein, aber beträgt im Durchschnitt 0 → viel Messfehler und somit tiefe Reliabiliät (und somit auch nur bedingt valide)
- \(E\) kann klein und im Durchschnitt 0 sein → wenig Messfehler, valide.
Die RoB-Checkliste von Cosmin hilft uns, für die drei Aspekte Raliabilität, Messfehler und Validität Studien kritisch zu beleuchten.
14.5.1 RoB-Analyse: Reliabilität
Sie sehen hier die Items der Cosmin RoB-Checkliste für die Reliabilität.
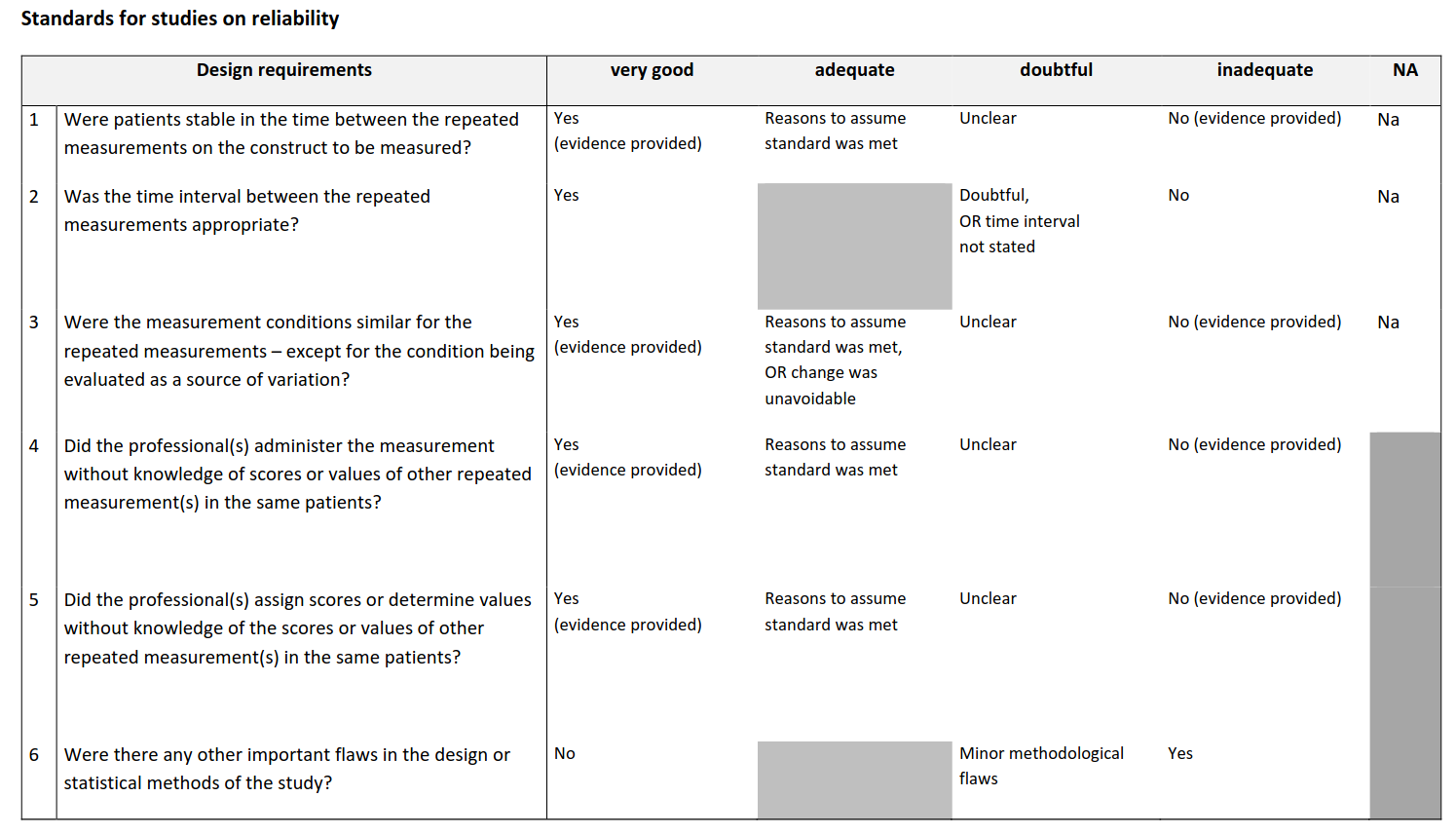
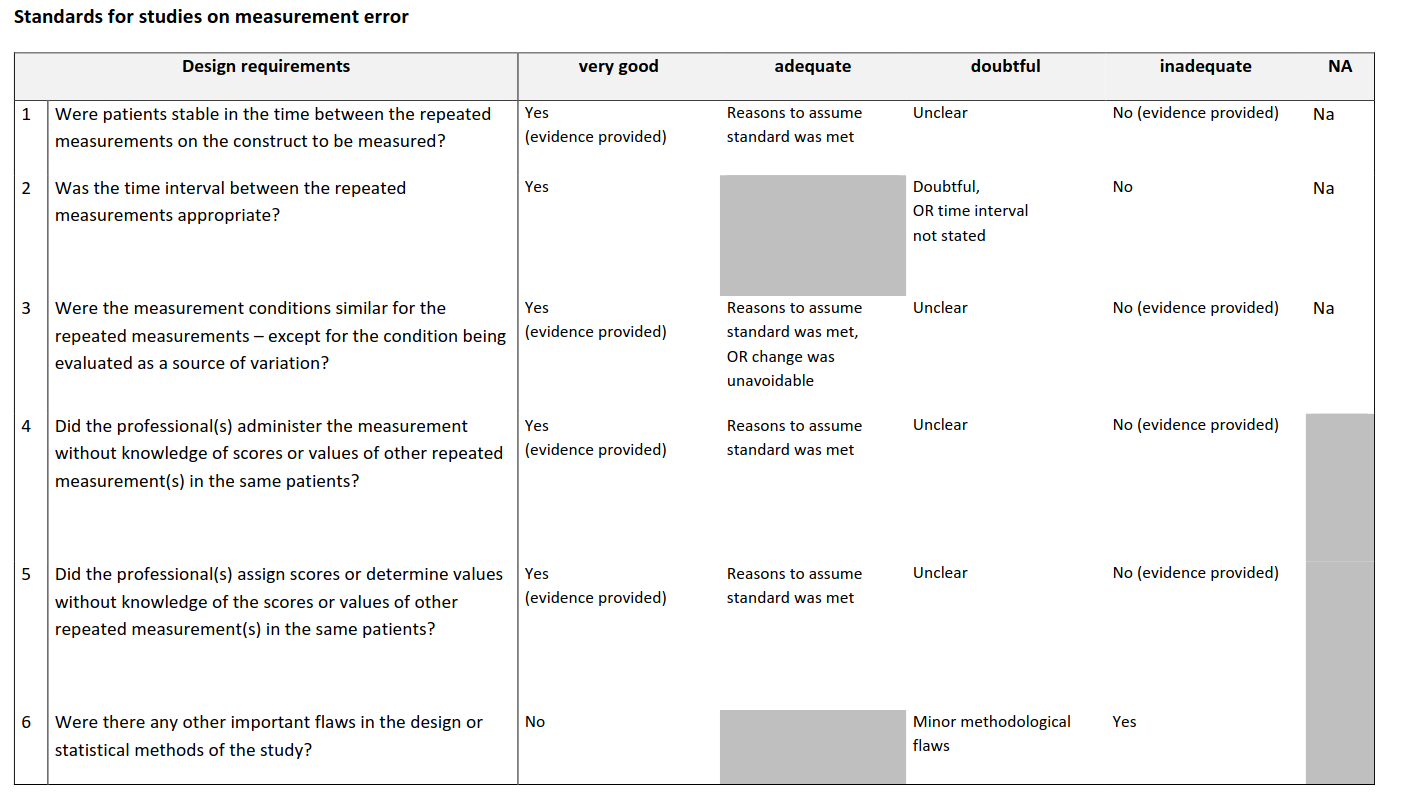
Were patients stable on the construct to be measured in the time between the repeated measurements?
Das Item prüft, ob sich der zu messende Zustand (das “Konstrukt“) der Person zwischen den beiden Messzeitpunkten nicht wesentlich verändert hat. Wenn sich der Zustand verändert, kann eine niedrige Übereinstimmung zwischen den Messungen nicht mehr klar der Messmethode zugeschrieben werden – sondern könnte einfach daran liegen, dass sich der wahre Wert geändert hat. Das ist wichtig weil:
- Reliabilität misst die Konsistenz eines Instruments, nicht Veränderungen im Konstrukt.
- Falls die Personen nicht stabil waren, würde man fälschlicherweise annehmen, dass das Instrument unzuverlässig ist.
- Die Stabilität ist also eine Grundvoraussetzung, um die Zuverlässigkeit korrekt einschätzen zu können.
Kurz gesagt: Wenn sich der “wahre Wert“ bewegt, während man die”Messgenauigkeit“ prüfen will, sind die Ergebnisse verfälscht – so wie bei einer Zielscheibe, die sich während des Schiessens bewegt.
Was the time interval between the repeated measurements appropriate?
Hier geht es darum, ob der Abstand zwischen den beiden Messungen so gewählt wurde, dass sich der wahre Wert des zu messenden Konstrukts nicht wesentlich verändert, aber auch nicht so kurz war, dass sich die Teilnehmer einfach an ihre Antworten erinnern oder durch Lerneffekte beeinflusst werden.
- Zu kurzer Abstand → Gefahr von Erinnerungseffekten oder Messung derselben Situation, nicht der Stabilität.
- Zu langer Abstand → Risiko, dass sich das Konstrukt real verändert (z. B. Krankheit fortschreitet oder bessert).
Der passende Zeitabstand hängt stark vom Konstrukt ab (z. B. Stimmung kann sich schneller ändern als Körpergrösse).
Were the measurement conditions similar for the repeated measurements – except for the condition being evaluated as a source of variation?
Das ist, als ob man denselben Kuchen zweimal backen will, um das Rezept zu testen. Man muss dafür dieselben Zutaten, denselben Ofen und dieselbe Temperatur nehmen, sonst testet man nicht das Rezept, sondern die Unterschiede in der Küche. Wenn sich Ergebnisse zwischen Messzeitpunkten unterscheiden, muss man also sicher sein, dass es nicht an den Messumständen (z. B. mehr Motivation, laute Umgebung, andere Beleuchtung) liegt.
Did the professional(s) administer the measurement without knowledge of scores or values of other repeated measurement(s) in the same patients?
Hier geht es nicht um das Bewerten, sondern um das Durchführen (Administering) der Messung selbst. Wenn der Untersucher weiss, welchen Wert oder welches Ergebnis ein Patient bei der ersten Messung hatte, kann das sein Verhalten bei der erneuten Messung beeinflussen — oft unbewusst. Dadurch wird die Messung nicht mehr objektiv, und die Reliabilität oder Messfehleranalyse kann verfälscht sein.
Did the professional(s) assign scores or determine values without knowledge of the scores or values of other repeated measurement(s) in the same patients?
Hier wird gefragt, ob die beurteilende Person beim Bewerten oder Scoren nicht wusste, welche Werte sie selbst oder jemand anderes bei früheren Messungen derselben Patienten vergeben hat. Wenn jemand z. B. dieselben Videos, Fragebögen oder Untersuchungen mehrmals bewertet (etwa um Intra-Rater Reliabilität zu prüfen), kann das Wissen über frühere Bewertungen die neuen Bewertungen unbewusst beeinflussen. Dasselbe gilt, wenn verschiedene Rater beteiligt sind und einer die Bewertung des anderen kennt.
Were there any other important flaws in the design or statistical methods of the study?
Dieses Item ist so etwas wie der “Auffangposten” in der COSMIN-RoB-Checkliste. Es fragt, ob es weitere gravierende Mängel im Studiendesign oder in den statistischen Auswertungen gab, die die Bewertung der Reliabilität (oder einer anderen Messgüte-Eigenschaft) beeinträchtigen könnten, auch wenn sie nicht schon in den vorherigen Items abgefragt wurden.
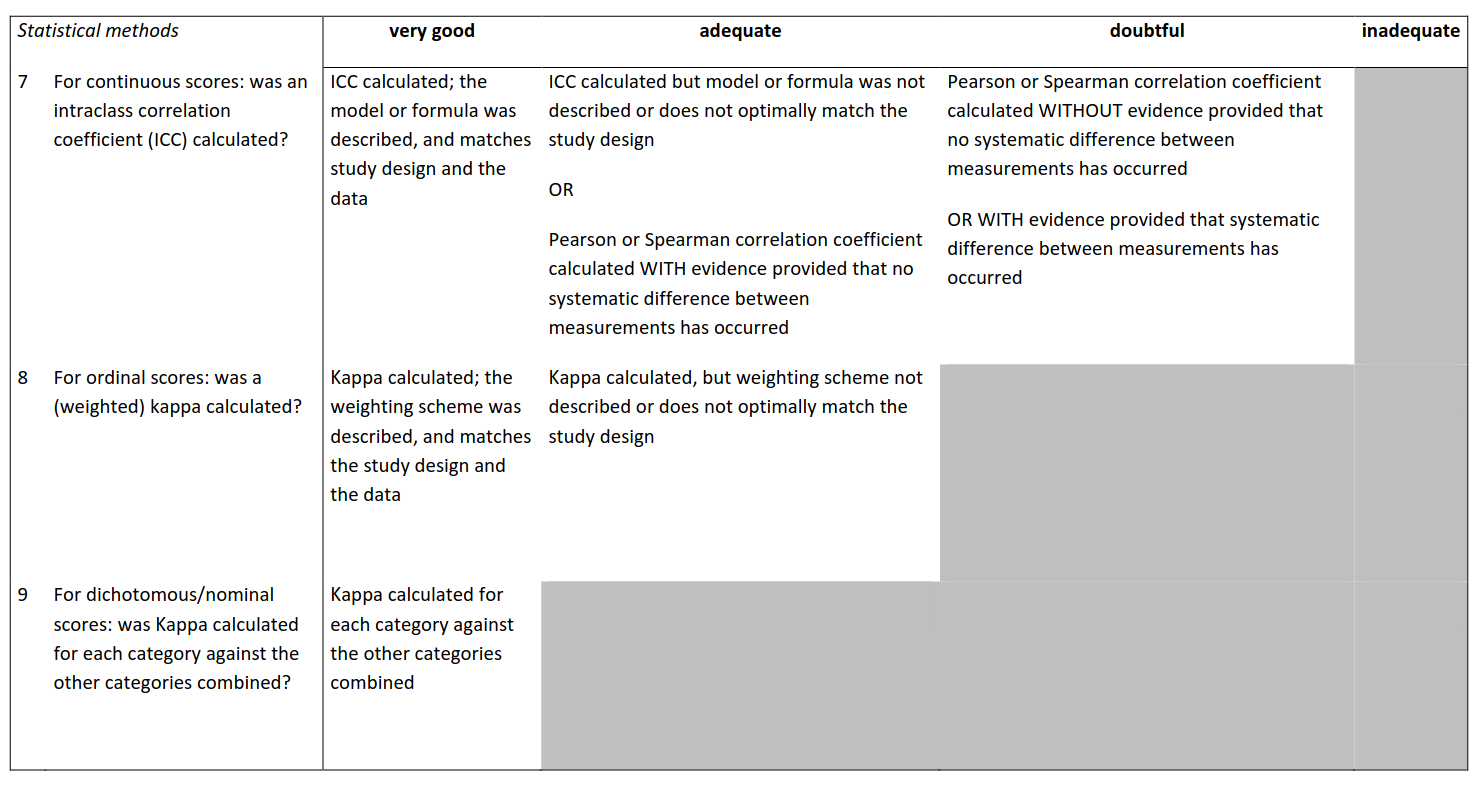
For continuous scores: Was the appropriate intraclass correlation coefficient (ICC) calculated?
Sie kennen den ICC und wie man diesen interpretiert. Welche Art von ICC die richtige ist, können Sie anhand der Kenntnisse aus den WA-Modulen nicht beurteilen. Schauen also in erster Linie, ob ein ICC und keine Korrelation berechnet wurde.
For ordinal scores: was a weighted kappa calculated?
Bei ordinalen Daten hingegen gibt es eine Reihenfolge und daher sollte ein gewichteter Kappa-Wert berechnet werden. Z.B. wird dann eine Abweichung bei einer Muskelkraft-Testung von M3 versus M5 stärker bestraft, als M3 versus M4.
For dichotomous/nominal scores: was Kappa calculated for each category against the other categories combined?
Auch diesen Wert kennen Sie von oben. Dieser sollte bei dichotomen oder nominalen Outcomes berechnet werden.
14.5.2 RoB-Analyse: Messfehler
Sie sehen hier die Items der Cosmin RoB-Checkliste für den Messfehler.
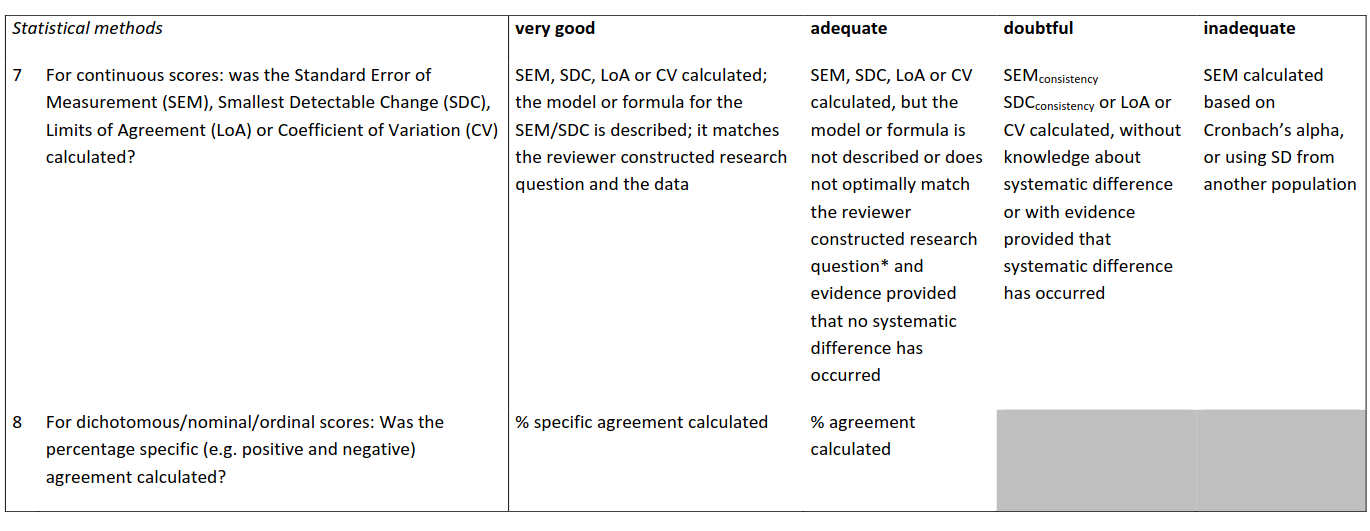
Im Vergleich zur Reliabilität sind nur die Statistik-Items anders.
For continuous scores: was the Standard Error of Measurement (SEM), Smallest Detectable Change (SDC) or Limits of Agreement (LoA) calculated?
Sie kennen die beiden Werte von oben. Auch hier gibt es verschiedene Methoden, den SEM oder den MDC (=SDC) zu berechenen. Für Sie ist wichtig, dass die beiden Werte berechent und rapportiert werden.
For dichotomous/nominal/ordinal scores: was the percentage (positive and negative) agreement calculated?
Das Item fragt, ob die Studie neben allgemeinen Reliabilitätskennwerten auch die prozentuale Übereinstimmung angegeben hat – getrennt für „positive“ und „negative“ Fälle.
- Positive agreement: Anteil der Fälle, bei denen beide Messungen ein „positives“ Ergebnis ergaben.
- Negative agreement: Anteil der Fälle, bei denen beide Messungen ein „negatives“ Ergebnis ergaben.
14.5.3 RoB-Analyse: Kriteriumsvalidität
Sie sehen hier die Items der Cosmin RoB-Checkliste für die Kriteriumsvalidität.
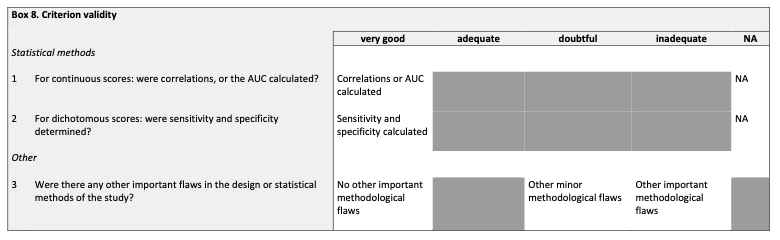
Die beiden zusätzlichen Items beziehen sich ebenfalls auf statistische Werte. Bei kontinuierlichen Variablen sollte eine Korrelation (wie stark korreliert das Assessment mit dem Goldstandard) oder eine Area Under the Curve, kurz AUC rapportiert werden. Eine AUC ist dann relevant, wenn mit einem kontinuierlichen Merkmal eine Diagnoste gestellt werden soll. Ein gutes Beispiel ist der Blutzucker. Dieser ist kontinuierlich und anhand des Blutzuckers möchte man z.B. feststellen, ob ein Schwangerschaftdiabetes vorliegt. Eine AUC von 1 bedeutet dann, dass es einen perfekten Cut-off gibt, um zwischen Frauen mit und ohne Schwangerschaft zu unterscheiden (perfekte Sensitivität und perfekte Spezifität). Eine AUC von 0.5 hingegen bedeutet, dass man anhand des Blutzuckers nicht unterscheiden kann.
Bzgl. des zweites Items ist zudem zu beachten, dass für die Spezifität und die Sensitivität Konfidenzintervalle angegeben werden. Die sind oft sehr breit, was die Aussagekraft der Studie relativiert. Auch die Vor-Test-Wahrscheinlichkeit, bzw. die Prävalenz sollte angegeben werden.
14.5.4 Gesamturteil der RoB-Analyse
Sie können jedes Feld ausfüllen und anschliessend die “Worst-Score-Counts”-Methode verwenden, um die Gesamtqualität einer Studie zu bestimmen (d. h. man nimmt die niedrigste Bewertung, die in einem Feld vergeben wurde). Beispiel: Wenn in einer Reliabilitätsstudie ein Kriterium in einem Feld als “ungenügend” bewertet wird, wird die gesamte methodische Qualität dieser Reliabilitätsstudie als “ungenügend” eingestuft.
Die Antwortoption “NA” (nicht anwendbar) ist nur bei manchen Studien relevant. Ist das Item nicht anwendbar, dann wird dieses nicht in die “Worst-Score-Counts”-Bewertung für diese Studie einbezogen.